パチョ奮闘記
2005年2月
■ このページについて ■
パソコン関係の雑記。ソフトからハードまでまんべんなく。
2001年が最盛期で、「テキストだけで90KB」もザラ。
一時期おとなしくなったけど、管理のCGI化によって息を吹き返し中。
絵日記CGI〜序章
2005.2.5.Sat
久しぶりにCGIを作ることになりました。自分用でなく彼女様のサイトで使うためのものです。ものとしては絵日記で、今はホムペビルダーでいちいちHTMLを作ってアップしてるものを、CGIで自動化しようという目的です。
というのも、この絵日記は姉妹で交互に更新している関係上、近い将来に無理がきます。今は二人とも実家だから問題ないですが、いつどっちが結婚してもおかしくない状況であり、そうなると日記を書く前にファイルをダウンロードする必要が出てきます。これはひどく面倒くさいことです。
サイト自体はsiteCTSと同じサーバーに収容してるし、せっかくCGIが使えるんだから今のうちに移行しておこう、と。
もちろんその辺の配布CGIを使ってもいいんですが、デザインの自由度は低いし、著作権表示とか細かいことぬかすし、せっかく彼氏がPerl使いなんだからスペシャルメイドのCGIを作ってあげましょう、ということです。
ベースはこのコンテンツで使われている管理CGIです。これに必要な機能をつけて不要な機能を省いて、新しいものを作り上げます。スペシャルメイドということで用途に特化させるので、別物になるだろうけど。
引用符選択マクロ
2005.2.11.Fri
新しいマクロを作りました。引用符の中身を選択する秀丸マクロ。HTMLとかプログラムとか書いてると、使用頻度の高いマクロです。
すでに他人様の作った類似マクロが入ってるものの、エスケープを認識してくれないのが不便だなぁ、と。なら自分で作ってしまえ、と。
マクロの仕様
- 引用符の中で実行すると、その中身を範囲選択
- そこからさらに重ねて実行すると、引用符も含んで範囲選択
- エスケープを自動認識
- 二重引用符と単引用符を識別
結論。無理。
引用符はカッコと違って「始まり」と「終わり」の区別がないので、どこからどこまで範囲選択すりゃいいのかわかりません。一応「カーソルの前にある引用符を探して、それに対応するものを探す」でやってみたものの、
"abc = '123';"
なんてあった時、セミコロンの上で実行するとよくないことになります。
だからといって abc = の上で実行しなきゃいけないような制限は「出来の悪いマクロ」です。
また、エスケープの自動認識も難題です。エスケープ自体もエスケープできるから
"\"" "\\" "\\\" "\\\"\\"
なんてのがありうるわけで、すべてのパターンに対応させるのはとても無理。
それでも頑張って作ってはみたものの、はっきり言って使いものになりませんでした。
→引用符を選択するマクロ Ver.100b
- 追記:2005.3.3
-
なんとか(自分で使う分には)問題ないくらいにできました。すごいです俺。
でも癖がかなり強いので、他人様が使える代物じゃありません。
→引用符を選択するマクロ Ver.101b
絵日記CGI〜鬼門のバイナリ
2005.2.12.Sat
今までスクリプト言語っていうかJavaScriptとPerlと秀丸マクロしかまともに使えない私にとって、「バイナリ」というのは鬼門だったりします。
アップロードされてきた画像をどうやってサーバーへ入れるのか今まで考えたこともなかったけど、そんな素人でも cgi-lib.pl で簡単楽々。
が、これを使えば簡単楽々というとこまではすぐに調べられるものの、これをどうやって使うのかが問題です。こんな高度なライブラリを解読できるほどPerlスキルは高くありません。
まぁ有名なライブラリだから方々に講座サイトがあるに違いない、と探しまわること数時間、ようやく使い方がわかった頃には日が暮れていた今日一日。
ローカルもレンタルサーバーもせっかくPerl5が入ってるんだし CGI.pm を使えばよさそうなものだけど、用途が「画像を受け取るだけ」である以上、あんな高性能モジュールはオーバースペック。規模の小さい cgi-lib.pl でさえ、使わない関数を勝手に消してサイズを半分にダイエットしちゃったくらいだし。
そうこうして、ようやく画像アップロード部のコードが完成。肝心のログ処理とかHTML生成とかがまだ手つかずだけど、これらはベースCGIをいじくるだけなので楽であると期待します。
最強マウスの弱点
2005.2.17.Thu
![[ CK-87MX×2 / 64KB ]](/lfs/psn/05/0217ck87mx.jpg "クリックすると拡大 / 64KB") 我が家のキーボード&マウスはロジクールのCK-87MXをご使用です。しかも2セットあります。ワイヤレスですが、セットモデルゆえにレシーバーひとつですむのが省スペースで良い感じです。
我が家のキーボード&マウスはロジクールのCK-87MXをご使用です。しかも2セットあります。ワイヤレスですが、セットモデルゆえにレシーバーひとつですむのが省スペースで良い感じです。
マウスはシームレスなデザインが美しいMX700で、どこぞのワイヤレスマウスと違って反応もリニアだし、クリック感もしっかりしていて心地よく、なかなかのお気に入りです。ちょっと重いのが難だけど。
つまりMX700が2つあるわけですが、片っぽは去年の10月に修理したばかりなので新品同様です。なんか左ボタンを押しただけでダブルクリックになってしまう症状が現れたので交換してもらいました。
この故障、なにが怖いって左ボタンを押しただけでダブルクリックになるという現象そのものです。つまり怪しげなファイルがデスクトップに転がってたとして、それをごみ箱へ捨てようと左クリックでつまんだ時点で実行してしまうわけです。だからすべて右クリックでやらないといけないのです。もちろん左ドラッグができないから、範囲選択も不可能です。こんな苛々することもありません。
最初はOSとかドライバとかソフト面が原因かと思ってたものの、同じものをもう1セット持ってたのが幸いし、マウス本体の故障だと断定できました。もうひとつのマウスにすれば症状は起きないし、問題のマウスを他のPCへ持っていくと症状が再発。もう間違いなしです。
でも、ネットで調べてみてわかったんですが、この手の故障はよくあるみたいですね。
さて。
最近になって、今度はもうひとつのMX700にこの症状が現れ始めました。もしかして弱いんでしょうか、ここ。独特の心地よいカチカチというクリック感は、わざと出している(そういう機構をわざわざ搭載している)と本で読みました。
そのせいかどうかは知りませんが、もしかして弱いんでしょうか、ここ。それとも用もないのに左ボタンをカチカチしてるのが悪いんでしょうか。(だって心地よいんだもの)
なんにせよあんな苛々は二度と御免ですから、今回はさっさと修理に出しました。そして今日、修理を終えて帰ってきました。やっぱり新品になって帰ってきました。修理内容には「故障内容が確認できませんでしたが、念のために同品と交換しました」と書いてありました。
たぶん、ちょこっとしかテストしなかったんでしょうね。まだ初期症状の段階で出しちゃったし。だんだんひどくなってくるってのが、またタチが悪い。
で、両方とも保証交換をしてもらったわけですが、きっとまた壊れます。メーカー保証は5年間、購入してから2年半。また壊れても交換してくれますよね?よね?
交換の対応をしてくれたヨドバシのお兄ちゃんが俺のことを知ってて驚きました。なぜ俺の正体を知ってるんだろう。
絵日記CGI〜現行CGIとの比較
2005.2.20.Sun
こつこつ進めて、だいぶ完成が見えてきました。
配布用としても耐えられる設計にしたため、予想通りすっかり別物。(もちろん配布予定などないわけだけど、そのつもりで作った方がしっかりしたものになります)
今回の肝は、なんつってもCGIは管理専用で動くことでしょうかね。CGIは記事の投稿をログに追加し、それをもとにHTMLを作ったり過去日記の管理をしたりするだけで、閲覧者には管理人が手書きでHTMLを作ってるのと見分けられません。
| ここで使ってるCGI | 今作ってるCGI | |
|---|---|---|
| XHTML1.1対応 | ○ | × |
| HTML生成 | ○ | ○ |
| 指定日のみ表示 | ○ | × |
| 最新月のみ新し順表示 | ○ | ○ |
| ローカル連動 | ○ | × |
| 複数コンテンツ管理 | ○ | × |
| バックナンバー管理 | ○ | ○ |
| クイックエディット | ○ | ○ |
| リアルタイムプレビュー | ○ | ○ |
| カキコモード | ○ | × |
| HTMLテンプレート | △ | ○ |
| 自動バックアップ | △ | ○ |
| バックアップ管理 | × | ○ |
| 画像アップロード | × | ○ |
| 画像管理 | × | ○ |
| 記事の削除 | × | ○ |
| ユーザーカスタマイズ | × | △ |
| cookie対応 | × | ○ |
| 管理モード | × | ○ |
| 認証方式 | パスワード+IP | パスワード |
| 使用ライブラリ | jcode.pl |
jcode.pl |
こんな感じ。記事の削除に対応してるあたり、配布用を前提に作ってることが象徴的に出てます。(くどいけど配布する予定はない)
必要な機能を追加して不要な機能を削除しただけではあるけど、内部的にはだいぶ複雑になったし、プログラムサイズも増えました。これは保守性やメンテナンス性、安全性を考えた結果であり、つまりはそこが自分専用と他人専用の差と言えます。
完成まであと少し。デバッグが充分ではないのでデビューはまだ先の話かな。
次の悪夢
2005.2.21.Mon
いよいよきますなぁ。IE7。ベータ版が夏頃にリリースされるそうで。ブラウザ界の重鎮であり巨人であるIEがメジャーバージョンアップするとなれば、業界の動きも慌ただしくなるというものです。俺もスキルの大部分がネットワーク関係に偏ってるので、気にしないわけにはいきません。
最大のシェアを誇るWindowsにおいて、最大のシェアを誇るIE。対抗するGecko・Opera陣も健闘してはいるものの、まだまだ微々たるものに過ぎません。(最近はFirefoxが躍進してるけど)
Windowsにデフォルトで入ってて普通に使う分には性能も充分、そしてデファクトスタンダードとなれば、この状況は納得できます。
人類が生み出した史上最悪のブラウザとかWebの最大の過ちはIEの誕生を許してしまったことであるとか散々な言われようですが、IE7の登場でどう変わるのでしょうか。
IEに疑問を抱かない人は、ちょっとでいいからWeb関係のスキルを身につけてみましょう。スタイルシートでもJavaScriptでもCGIでも、なにをするにでも立ちはだかるのが「IEの壁」です。様々な種類が混在するコンピュータの世界において、「仕様」というのはとても大事です。特にネットワーク関係ではまったく異なる相手と通信するわけで、ことのほか重要です。
そして、IEはこれをことごとく無視する存在です。しかもこれだけの普及率を誇るブラウザですから、無視するわけにもいきません。結果として、仕様の方が引きずられます。時にはWebサーバーにも変更を強要するほどであり、まったくもって厄介な存在なのです。
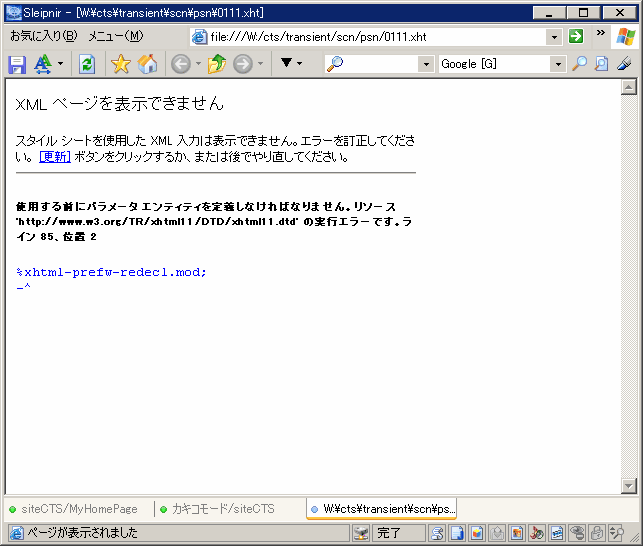
たとえば、HTMLのコンテントヘッダは text/html です。一方、当サイトも採用している新規格のXHTML1.1では application/xhtml+xml になりました。他のブラウザはもちろん対応していますが、IEではこれを指定するとダウンロードダイアログに化けます。だからといって無視できる数でもないわけで、泣く泣く text/html にするしかありません。(とりあえず現時点では表示上の問題は起きないし)
今の主流であるHTML4.01では、文書型宣言は
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
のように書きますが、XHTML1.1では大きく変更されて
<?xml version="1.0" encoding="EUC-JP"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
のように書きます。しかし、IEではこれを書くとローカルで表示できなくなります。自分でHTMLを書いてる人は普通ローカルで確認しながら書きますから、こんなの致命的もいいところです。(俺はサーバーを立ててるので支障ないんですが)
{kind=link}
また、今のブラウザはこの文書型宣言を見て、ちゃんとした仕様準拠のHTMLか滅茶苦茶なHTMLかを判断し、表示モードを変えます。一般に「標準モード/互換モード」とか「DOCTYPEスイッチ」とか呼ばれる機能です。仕様を優先して表示するか、今までの慣習を優先するかの違いです。ところどころで表示が異なります。特にスタイルシート。
そして、ここでもIEは邪魔します。
IEは <!DOCTYPE> 宣言の前に改行以外の文字が入ると強制的に互換モードになる。
つまりは <?xml version="1.0" encoding="EUC-JP"?> の行です。従って、XHTMLにすると標準モードが使えません。それでいて他のブラウザではちゃんと標準モードになるわけですから、画面デザインのすべてをスタイルシートに任せないといけないXHTMLでは致命的どころの騒ぎじゃないのです。
どうですか、こんなIE6。XHTMLひとつ採用するだけで、致命的な欠点が3つも露呈するのですよ。もちろん、こんなのは氷山の一角に過ぎません。
ライバルであるGecko・Operaと比べても、圧倒的なレンダリングの遅さ、今の時代の要であるスタイルシートへの弱さ、Webを振りまわす身勝手な仕様、そして致命的なセキュリティバグの数々。一番普及しているブラウザは、一番性能の低いブラウザでもあるわけです。
そんな散々だったIE6を、IE7はどう変えてくれるのかでしょうかね。多くの人が一刻も早い改善を熱望して幾数年、ようやくおでましです。2003.5.5にもちょっと書きましたが、WinXP専用というのも、どうやら事実のようです。しかもSP2が必須だそうです。
根拠のない噂だと信じたかったのですが、それを本当にやるのがMicrosoftということですね。
いや、それにしてもXP専用ですか…。それはつまりXP未満のWindowsが生き残ってる限りIE6は不滅を意味するわけで、今から気絶しそうです。Win9x系のサポート打ち切りは仕方ないにしても、Win2000まで切って捨てるとはなぁ…。ここ数年のMicrosoftって旧型の足切りがちょっと大胆すぎません?
ともあれ、個人的にはタブブラウザ化とかそういうのはどうでもいいから、上記のような激しいバグだとかいかがわしい仕様違反だとかスタイルシートの弱さとか、そういうのを直すまっとうな進化を希望する次第です。大部分の素人はそういう内部的なことがわからんのでメーカーはついつい見た目の装飾ばかり気にしがちですが、ガワばかり気にしてると本当にGeckoに足をすくわれるよ、と。
そのGeckoも、Mozilla・Netscapeときて、先日Firefoxが誕生したけど、なんかものすごい普及速度らしいですね。1ヵ月で1000万ダウンロードってすごいですよ。シェアもあっという間に7%を超え、IEのシェアを90%以下に落としこんだ功績は大きいです。この調子で邁進してほしいものですな。
![]() というわけで協力してみる。
というわけで協力してみる。
世界的にはユーザーのIE離れが進んでます。IEに不満を募らせていたからこそ、Firefoxがこうして話題になったりもします。日本でも経済産業省がガイドラインを作成するなど、Windows一辺倒の風潮もだいぶ風向きが変わってまいりました。
あと20年も経てば、「昔はそりゃもうひどいOSが業界を食い荒らしていてねぇ…、あの頃はひどかった」なんて昔話ができるかもしれませんな。
…と、好き放題書いてる俺だけど、なにを隠そうIE派だったりします。ただしSleipnir。
IE4の登場以降、OSとブラウザの癒着は散々叩かれてきたけど、それは一方で親和性が高まるということでもあり、逆説的には「もはやそれくらいしかIEを使うメリットがない」とも言えるんですが、ちゃんと使えばJScriptも便利な代物なのです。(JavaScriptの知識に少し上乗せするだけで使えますし)
IE上で動くレジストリエディタとかアプリケーションランチャーとかいった危険なものを自作している俺だから、他のブラウザを常用する気にはなれないのよね。
絵日記CGI〜自動バックアップ
2005.2.22.Tue
絵日記CGIがようやく完成の兆しです。
このCGIには自動バックアップ機能があり、投稿した記事をバックアップログへ追記していきます。編集しても前の記事は残っているから、操作を誤った時の保険になります。一方で、どんどん追記していくので、放っとくとサイズが無限に増えてしまいます。
よって、古いバックアップを自動削除する仕組みを用意しないといけません。手動で定期的に削除すればいいだけの話だけど、人間はそんなマメにはできてないですよね。
そんなわけで、
sub readjustBackupDir {
my $limit = $env{backuplimit} *1024; #上限サイズ
my $dir = $env{backupdir}; #対象ディレクトリ
foreach (&virus::read($dir)) {
#(上限サイズ < 対象ディレクトリのサイズ) なら削除
unlink("$dir$_") if ($limit < &virus::getSize($dir));
}
}
…という機構を用意してはみたものの、ファイルのリストが入る配列は年月順に並んでいるため、これだと「古い年月から削除していく」になってしまうのに気づきました。たとえば一番古い年月の日記を編集した時に制限サイズを超えてしまったら、その場で削除されてしまうことになります。これではバックアップの意味がない。
というわけで、「上限サイズを超えたら最終更新日が古い順に削除」に直すことにしました。
sub readjustBackupDir {
my $limit = $env{backuplimit} *1024; #上限サイズ
my $dir = $env{backupdir}; #対象ディレクトリ
my @file = &virus::read($dir); #ディレクトリのファイルリスト
# $_ = "更新日の積算秒::対象ディレクトリ/ファイル名" にする
foreach (@file) {
$_ = &virus::getLastupdate("$dir$_"). "::$dir$_";
}
@file = sort(@file); #配列を更新日順にソート
foreach (@file) {
#(上限サイズ > ディレクトリサイズ) になったらループ終了
last if ($limit > &virus::getSize($dir));
unlink((split(/::/))[1]); #積算秒の部分をカットして削除
}
return;
}
こういうモジュール的関数を作る時はいかにエレガント && コンパクトに組めるかを非常に気にする俺だけど、知識の足りない現状ではこれが精一杯。美しくない…。
修正前はサイズが上限値以下になっても最後まで空ループしてたけど、これもついでに直しました。一見小さいことに見えますが、もしバックアップファイルが100万個あったとしたら、上限値を1バイト超えてファイルをひとつ削除すると、残りの99万9999回は無駄なループになるわけで、とても大事なことなのですよ。共有サーバーでの運営なんだから、サーバーリソースは大事に使いましょう。
ともあれ、ファイルが絡むものはデバッグが面倒くさくていかんです。上限サイズを超えるまでファイルをコピペで増やして実行、うまく動かなかったら修正してまたコピペで増やして…。
なお、上記で使われてるパッケージ &virus:: は、自前のライブラリです。
絵日記CGI〜排他処理
2005.2.23.Wed
考えてみたら、排他処理をつけるの忘れてました。複数から同時に書きこまれた時にファイルが破損するのを防ぐアレ。掲示板やカウンターには必須の機構。
この絵日記CGIは管理人しか書きこめないので本来は不要なのだけど、なにせ二人で交互に書いているコンテンツ。ファイルを開いて記録して閉じるまでの時間なんてコンマ何秒にも満たないものの、書きこみする人間が二人になった時点で可能性はゼロではなくなります。つまり、排他処理は必要な機構です。
とりあえず俺、排他処理が必要なものなんて今まで作ったことがなく、従って付け焼き刃程度の知識しかありません。しかもここは絶対にバグを出しちゃいけないとこなので、自分で組むのは危ないです。
ということで、知識が追いつくまでは他のスクリプトを拝借することに。
ファイルロックにはPerl側で専用の flock 関数が用意されているものの、これは使えるサーバーが限られます。だから多くの配布CGIでは symlink や mkdir 式が多く使われているけど、これらは完全ではないそうです。
で、排他処理について調べてる途中で見つけた、この関数を使わせてもらうことに。
sub my_flock {
my %lfh = (dir => './lockdir/', basename => 'lockfile',
timeout => 60, trytime => 10, @_);
$lfh{path} = $lfh{dir} . $lfh{basename};
for (my $i = 0; $i < $lfh{trytime}; $i++, sleep 1) {
return \%lfh if (rename($lfh{path}, $lfh{current} = $lfh{path} . time));
}
opendir(LOCKDIR, $lfh{dir});
my @filelist = readdir(LOCKDIR);
closedir(LOCKDIR);
foreach (@filelist) {
if (/^$lfh{basename}(\d+)/) {
return \%lfh if (time - $1 > $lfh{timeout} and
rename($lfh{dir} . $_, $lfh{current} = $lfh{path} . time));
last;
}
}
undef;
}
sub my_funlock {
rename($_[0]->{current}, $_[0]->{path});
}
公開サイト → 技林 / スクリプト制作メモ / ファイルロック(排他処理)について
これならたしかに強そうだし、なにより俺にも理解できます。「自分に理解できる」というのは、自分用に最適化できるということですから、とても重要なポイントです。
早速組みこんでみたところ、Windowsサーバーでもちゃんと動くし、やってることはファイルのリネームだけなので、なんとなくエレガントです。symlink 式はWindowsサーバーでは動かないし、ましてや mkdir 式みたいに「空ディレクトリを作って、それが存在する時はロック中」なんて美しくない方法は使いたくないです。(なにをもって「美しい」とするのかは知りませんが)
ともあれ、考えてみたら人の作ったモジュールを使うのって初めてです。jcode.pl や cgi-lib.pl などのライブラリはまぁ別格として。
今までは意地でも「俺製100%」にこだわってきたけど、Perlはだいぶ本格的な言語であり、JavaScriptのようにはいかんのですよ、ということで。
絵日記CGI〜リファレンス演算子
2005.2.24.Thu
昨日の最後の方で「なにより俺にも理解できる」などと吹聴しましたが、正確には1ヵ所だけ理解できてないところがあったりします。
return \%lfh if (rename($lfh{path}, $lfh{current} = $lfh{path} . time));
return \%lfh if (time - $1 > $lfh{timeout} and
の2行。
\%lfh
ってなんぞや?
%lfh は言うまでもなくハッシュ変数(連想配列)だけど、頭についてる \ はなんだ。そのエスケープには一体どんな意味があるというのだ?
この不可思議なエスケープは今までも何度か見てきたけど、未だに意味がわかりません。手元にあるプチリファレンス Perl/CGIにも載ってないし、解説してある講座サイトも見たことがない。
「見つけられないということは、まだ知るべき時期がきてないということである」という考えをもっているので今まで放ったらかしだったけど、「知りたくなった時が知るべき時である」であるからして、この機会に調べておくことにしました。
でも、どうやって調べればいいのだろう。「"\%" perl」で検索すれば早そうだけど、検索語には \ が使えない。この記号がもつ意味は普通「エスケープ」ですが、「エスケープ perl」じゃ範囲が広すぎるし、そもそもこの場合はエスケープではない気がしてなりません。エスケープは「次の文字がもつ特別な意味を無効にする」であり、% を無効化したら変数ではなくなってしまいそうな気がしません?
エスケープではないなら、それとは違う名前がついてるはずです。その名前さえわかればこっちのもんなのに、それがわからない。あぁじれったい。
しかし、そこまで思いつけばかなり近づいたようなものです。つまり「バックスラッシュ 変数 perl」です。
んで、トップに出てきたサイトを見てみると、いた。\% やら \@ やら。そして俺の求めるキーワードが「リファレンス」であることも判明しました。
ところが、いつもなら「これさえわかればもう自由自在!」なのですが、「リファレンス 変数 perl」で検索したら結果がどうなるか、すぐにわかります。Perlのリファレンスが出てくるだけです。まったく、難儀な名前ですね。
…なんて懸念も無駄で、「トップに出てきたサイト」にその解説まで事細かに書いてありました。
なるほど、頭に \ をつけると、変数の中身でなく、そのアドレスを示すわけか。C言語のポインタみたいなものと解釈すればいいのか。
とりあえず実験スクリプトを組んでみます。
sub ref {
my $s = $_[0]; #4.渡されたアドレスを変数に格納
$$s = 1; #5.リファレンス先を書換($sではなく$$sなのがポイント)
}
sub test {
my $a = 0; #2.変数aに0を入れる(test関数内でのみ有効なローカル変数)
&ref(\$a); #3.関数refを実行($aの内容でなく、$aのアドレスを渡す)
print $a; #6.結果は1
}
&test(); #1.開始
ほうほうなるほど!面白いなぁ。
通常なら $a はレキシカルスコープのローカル変数なので外部からは一切干渉できないはずなのに、見事に書き換えられてます。
なによりの副産物は、この仕組みを使えばPerlでは不可能だった「関数への引数に複数の配列を渡せる」という事実でした。
sub test {
my %h = %{shift()}; # @_をshiftする
my @a = @{shift()};
}
&test(\%hash, \@array);
ほうほうなるほど。面白いなぁ!
いや、「関数への引数に複数の配列を渡す」なんてのはJavaScriptじゃあたり前にできるのに、Perlではできなかったんですよ。だから仕方なくグローバル変数にしたりしてたんだけど、なるほど、Perlでも可能なのね。これでもっと幅のある組み方ができるな。うむうむ!
99%まで完成していた絵日記CGIだけど、別に急いでるわけじゃないし、もうちょっと待ってもらおうかな。ちょっとゴリッと組み直したくなったぜ。
いやー、まさにSmart!サマサマですな。
ここが有用なサイトであるのはずっと前から知っていたものの、俺の大嫌いな「固定プチフォント」をやってるから入りたくなかったんです。
今回は知りたい情報のためだ…と妥協したけど、たとえマブダチのサイトであっても入らないほど大嫌いな俺としては、そりゃもう小難しい解説文よりも厳しい修行なのでありました。
雪降る日の懐事情
2005.2.25.Fri
![[ 雪景色 / 33KB ]](/lfs/psn/05/0225snow.jpg "クリックすると拡大 / 33KB") もうすぐ夜明けの一番寒い時間、灯油が切れたのでしぶしぶ買いに行こうと玄関を開けた時の物語。どうしたものか。
もうすぐ夜明けの一番寒い時間、灯油が切れたのでしぶしぶ買いに行こうと玄関を開けた時の物語。どうしたものか。
なんか今年はよく雪が降ってるような気がするものの、まだ一度も降ってる様を見てない。仕事の時は降らないし、仕事がない日は雨戸を閉めて引きこもっているせいでしょうか。一日中パソコンと向かい合ってるから、雨戸を開けていると眩しいんですよね。タイミングいいんだか悪いんだか。
雪はすでに止んでるものの、遠くのガソリンスタンドまで行くのは勘弁です。しかし、灯油はない。まぁエアコンとかホットカーペットとか毛布とかあるから凍死はしませんが、10000円をたびたび超えちゃう我が家の電気代(たぶん3分の1くらいはパソコンの飯代)を考えると、灯油がないことによるロスは痛いです。
去年の2月は229kWhだったのに、今月は408kWh。休みの多さを見事に反映してます。
で、今月のPCFanの表紙に「はじめてのサーバー自作ガイド」とか書いてあって思わず買っちゃったわけですが、これがまた全然役に立たない。言い方を変えれば、すでにサーバー立ててる奴の役に立つわけがない。
こういう大衆向け雑誌でも平気で特集組んだりしてるのを見ると、「自宅サーバー」もずいぶん浸透してきたんだなぁと思います。
まぁそれはいいとして、その中に「電気代」の項目があったわけですよ。サーバーは24時間起動が原則だから、電気代も大事な項目ですね。
そういえば、パソコンってどれくらい電気代がかかるのか、あまり深く考えたことがありません。ていうか考えないようにしてるって言った方が正しいのか。
その記事によれば、24時間あたりの電気消費量は
- 最新贅沢マシン(Pen4-3.6GHz / 915P)… 5.04kWh(126円)
- お手頃スタンダードマシン(Pen4-3.0GHz / 865PE)… 3.36kWh(84円)
- ちょっと古めバリューマシン(Celeron-2.6GHz / 865G)… 2.26kWh(66円)
- もはや化石マシン(Pen3-1.13GHz / 815E)… 1.92kWh(48円)
- ちょっと古いノート(モバイルPen3-800MHz / 810E)… 1.2kWh(30円)
くらいだそうです。千枝は CeleronD-2.4GHz / 865PE だから「ちょっと古めバリューマシン」くらいでしょうか。就役してまだ2ヵ月しか経ってないのに…。しかしPrescottコアだしグラボもあるしRAID組んでるしデュアルディスプレイだったりするので、電気代的にはもっと高いはず。
そして、千枝が起きてる時はファイルサーバーである雪子も同時起動してるわけで、これが Pen3-866MHz だから「もはや化石マシン」くらい。化石とは失礼な!まだまだ現役だよ!
これに加え、紗菜が自宅サーバーとして常時稼働してます。これはまぁ Pen2-266MHz だからかわいいものですね。
なにはともあれ、千枝がPrescottパワーで80円くらい使い、雪子は3連装HDを積んでるので50円くらいか、紗菜は10円としましょう。忘れちゃいけないけど、Pen3-1000MHz の小春もいます。でもこいつはほとんど出番がないので除外。
大体換算で、24時間140円。
ちなみにこれを書いてる現在、千枝は起動75時間めを突破し、雪子は92時間を突破し、紗菜は二度目の1000時間を突破してます。
{kind=link}
PCFanは「1日あたり缶コーヒー1本分程度の出費でサーバーを運営できるのだ」と気軽に言ってますが、どうも毎日缶コーヒーを買ったら月3600円になるということに気づいてないように思えます。月3600円というのは、ちょっとサーバーってやってみたいな〜程度の覚悟の人間に出せる金額ではありません。それなら毎日缶コーヒーを買った方がマシです。
さて、パソコンの飯代に月いくら費やしてるか考えるのが怖くなってきたところで、今夜はちゃんとパソコンの電源を切ってから寝るとしましょうかね。(もちろん紗菜以外ですが)
絵日記CGI〜記事削除機能
2005.2.26.Sat
今作ってる絵日記CGIはここで使われている管理CGIをベースに作られてるけど、ローカル連動機能がなくなったり画像アップロード機能がついたり色々ある違いの中で、一番象徴的なのが記事の削除に対応してるとこだと勝手に思ってます。俺は記事を削除することをしないし、なんらかの理由(間違えて投稿したなど)で消す時でも、自分で作ったものだからログデータの方を直接修正して消せます。
しかしこのCGIを使うのは俺でなく、彼女様とその妹様。プログラムの欠片も知らない素人様に、「消す時はログデータを直接修正してネv」なんて怖くて言えません。
そんなわけで記事の削除機能をつけているわけですが、なまじHTMLを自動生成するだけに処理が面倒くさいのです。ログファイル(1ファイル1ヵ月分)の中から1件(1日分)だけ消すのは簡単だけど、削除した時に1件もなくなった時、ログファイルを消さないといけない。CGIはログファイルの有無で記事の有無を判断するので、消さないと空のHTMLを作ってしまいます。おまけに、バックナンバーのリストにまで存在しない年月へのリンクを作ってしまいます。
if (…エラーチェック…) {
…エラーチェック…
} elsif ($query{delete}) { #削除指定
$_ = "$date<><><><><>\n";
} else {
…記事の書込処理…
}
「ログファイルの中から1件だけ消す」部分は、たった2行です。通常の書込動作の時に削除フラグを入れておき、「フラグが立っていたらなにも書きこまない」にすれば、削除したことと同じになるって寸法です。
問題なのは、先述したように「それによってログファイルに記事が1件もなくなった時」です。
sub logDelete {
my ($yy, $mm) = @_;
#指定年月のみチェック
if ($yy && $mm) {
my ($exist, $logfile) = (0, "$env{logdir}$yy$mm.$env{logext}");
foreach (&virus::read($logfile)) {
$exist = 1 unless (/^\d\d<><><>/);
}
unlink("./$yy$mm.$env{htmlext}") if (!$exist);
#すべてのログファイルを洗いざらいチェック
} else {
foreach (@logDirList) {
my ($exist, $ym, $logfile) = (0, substr($_, 0, 4), "$env{logdir}$_");
foreach $log (&virus::read($logfile)) {
$exist = 1 unless ($log =~ /^\d\d<><><>/); #記事がひとつでもあるか?
}
unlink($logfile) if (!$exist); #なければログファイルを削除
}
}
#ログリストを更新
@logDirList = &virus::read($env{logdir});
&refresh();
}
sub refresh {
#既存のHTMLの年月を見て該当年月のログがなければ削除
foreach (&virus::read('./')) {
if (/^((\d\d(0[\d]|1[012]))\.$env{htmlext})$/) { # /^((YYMM).html)$/
unlink ("./$1") unless (-e "$env{logdir}$2.$env{logext}");
}
}
foreach(@logDirList) {
&createViewHTML(substr($_, 0, 4)); #ログからHTMLを再生成
}
&createBackSelectHTML(); #バックナンバーリストのHTMLを再生成
}
ログへの書込が終わって処理が返ってきたら、再び削除フラグを見て、&logDelete() を実行します。不要なログを削除したら続いて &refresh() を実行し、HTMLを再生成。そんな感じ。
思ったより楽に作れたものの、それは今回の改造にあたってモジュール化をより細かくした(関数の単位あたりの仕事量を減らした)からこその恩恵であり、siteCTS版に同じ機能をつけようと思ったらこうはいきません。もう根本的につけないのを前提とした設計になってるもの。
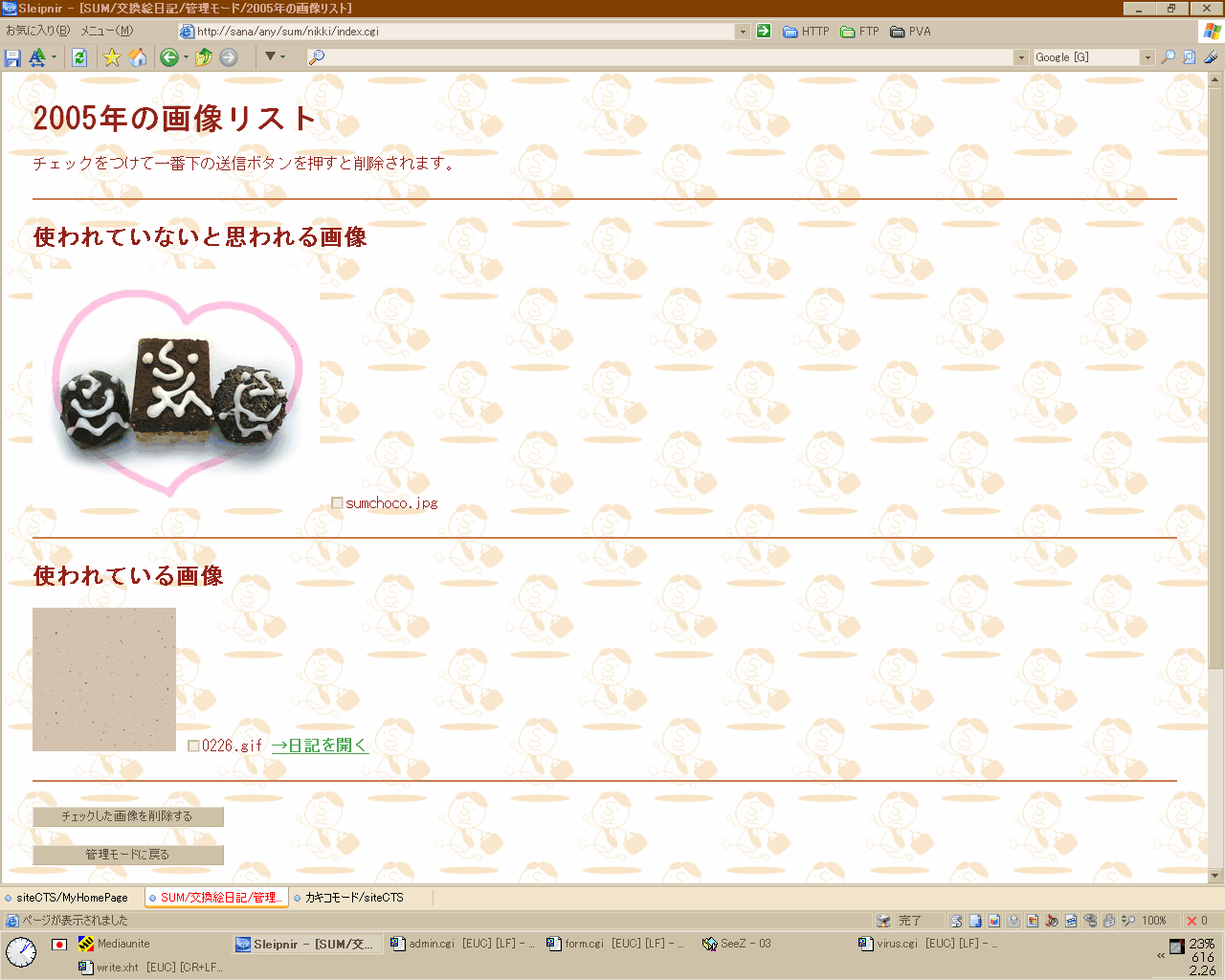
ただ、「絵」日記である以上、画像アップロード機能も実装してるわけで、記事を削除するなら画像も削除するべきでは? というのは迷いどころです。でも勝手に消すのも問題があるだろうと思い、画像管理モードの方に「リンクされてない画像をピックアップ」という機能を追加しました。
sub createImgList {
my %env = %{shift()};
my %query = %{shift()};
my ($YY, $MM, $DD, $Y, $M, $D) = @_; #クエリで与えられた日付
#使われている画像のピックアップ
my %usedImg;
foreach (&virus::read($env{logdir})) {
next if (substr($_, 0, 2) ne $YY); #クエリ年以外はスキップ
#ログを開いて$srcが入ってる月日にファイル名でフラグを入れる
foreach (&virus::read("$env{logdir}$_", 'chomp')) {
my ($date, $week, $writer, $img, $sentence, $appendix) = split(/<>/);
my ($src, $imgid, $align, $width, $height, $alt) = split(/<\+>/, $img);
$usedImg{$src} = 1 if ($src); $usedImg{0102.jpg} = 1;
}
}
#使用/未使用画像の振り分け
my (@use, @unuse);
foreach (&virus::read("$env{imgdir}$YY/")) { #クエリ年の画像格納フォルダ
push($usedImg{$_} ? @use : @unuse); #ファイル名が連想配列にあるか?
}
my ($i, $used, $unused) = (0, '', '');
#使われてない画像リストのHTML
foreach (@unuse) { # $_ = ファイル名
$unused .= qq( <p><img src="$env{imgdir}$YY/$_" title="$_" alt="[ $_ ]">\n <input type="checkbox" name="delete$i" id="delete$i" value="$_"><label for="delete$i">$_</label></p>\n\n);
$i++;
}
$unused = " <p>ありません。</p>\n\n" if (!$unused);
chomp($unused);
#使われてる画像リストのHTML
foreach (@use) { # $_ = ファイル名
my ($mm, $dd) = (substr($_, 0, 2), substr($_, 2, 2));
$used .=
qq( <p><img src="$env{imgdir}$YY/$_" title="$_" alt="[ $_ ]">\n).
qq( <input type="checkbox" name="delete$i" id="delete$i" value="$_"><label for="delete$i">$_</label>\n).
qq( <a href="./$YY$mm.$env{htmlext}#d$dd" target="_blank" title="新しいウィンドウ">→日記を開く</a></p>\n\n);
$i++;
}
$used = " <p>ありません。</p>\n\n" if (!$used);
chomp($used);
my $previewForm = &createPrevButtonHTML();
#テンプレート
my %s;
$s{subtitle} = "管理モード/$Y年の画像リスト";
$s{addclass} = ' admin';
$s{bodyid} = 'admin-imglist';
$s{body} = <<"hereDocument";
<h1>$Y年の画像リスト</h1>
<p>チェックをつけて一番下の送信ボタンを押すと削除されます。</p>
<hr>
<form action="$env{cginame}" method="post">
<h2>使われていないと思われる画像</h2>
$unused
<hr>
<h2>使われている画像</h2>
$used
<hr>
<p>
<input type="hidden" name="exec" value="admin-imgdelete">
<input type="hidden" name="password" value="$query{password}">
<input type="hidden" name="Y" value="$YY">
<input type="submit" value="チェックした画像を削除する">
</p>
</form>
$previewForm
hereDocument
&print(&admin::templateReplace(\%s)); #HTMLを出力
exit;
} #createImgList.end
(↑の画面表示結果)
{kind=link}
自分以外が使うことを前提にすると、こういうのも作らないといけないから面倒くさいですね。おかげでコードは爆発的に増え、その分だけ複雑になり、比例してバグも出やすくなります。
まぁこんな程度で飽和していたら、これから作ろうとしている新型CGIなんて到底無理です。なにせコメント機能とかカテゴリ機能とかちょっとブログを意識してるっぽいものを計画してるだけに、今のうちに少しでも経験値を稼がねばなりません。(レンタルサーバーのオプションでMovableTypeが簡単設置できるんだけど、もちろん使う気はない)
絵日記CGI〜初心忘るべからず
2005.2.27.Sun
せっかく「あとはデバッグするだけ」ってとこまで完成していた絵日記CGIをバラして再構築しながら、痛感しました。
本当、なにも知らないのねぇ俺。
まぁ数えるほどしか組んでないので当然なんだけど、Perlスキルの低さを改めて思い知らされます。
そして、悔しいような嬉しいようなというこの感覚が、なんだか懐かしい。
なにも知らないということは、知ることすべてが初めてということです。それは、ひとつ知るたびに「できること」がひとつ増えるということです。否、いくつも増えることだってあります。
それは多分に本能的な快感…そう、JavaScriptを始めたてだったあの頃の気分です。いや、HTMLを始めた時もCSSを始めた時もそうでした。そして憶えるものがなくなってきて刺激に飢えると、新しい刺激を求めてステップアップしてきたんです。
ひとつ知るたび、そんな快感をひとつずつ失くしていくかと思うと、なんだか嬉しいような寂しいような、複雑な気分です。HTMLもCSSもJavaScriptもほとんど憶え尽くしてしまい、そういった快感はもう得られません。
果たして、Perlを食い尽くした後はどうするんだろう。コンパイラ言語に進むことは一生なさそうな気がするし、CGIで作りたいものがまだまだ山ほどあるので、やっぱりRubyかPHPかなぁ…。
まぁステップアップしたからといって学ぶのをやめるわけではないので、そんなに手は広げられないんだけどさ。
ともあれ、ようやく基礎知識が身についたようで、いよいよ「伸び盛り」の時期にさしかかってきました。このくらいになると自分がどんな処理をよく使うかがわかってくるので、そういうのは積極的にモジュール化して自作ライブラリの virus.pl に登録します。新しいCGIを作るたびにサイズが増えて、現在500行/11KBになってます。
今回一番大きく変更されたのは、ファイルに出力する write 関数です。
■改修前
sub write {
my $path = shift(@_);
if (substr($path, 0, 1) ne '>' && substr($path, 0, 2) ne '>>') { #先頭が > でも >> でもない
$path = ">$path";
}
my $line = ($_[1] ne '') ? join('', @_) : $_[0]; #配列だったら結合
open(WRITE, "$path") || &error("write error $path at &virus::write()");
print WRITE $line;
close(WRITE);
}
&virus::write($path, @list); #実行
&virus::write(
"ファイルのパス",
"書きこむ内容(スカラかリスト)"
);
■改修後
sub write {
my ($path, $line, $lockdir, $busyfunc, $lockfile) = @_; # $lineと$busyfuncはリファレンス
$lockfile = 'lock' if (!$lockfile); #デフォルトロックファイル名
&chop($lockdir, '/'); #尻に / がついてたらカット
#エラーチェック
&submitError('CGIのバグでーす') if (
($lockdir && ref($busyfunc) ne 'CODE') || #ロックエラー用の関数が渡されてない
!(ref($line) =~ /SCALAR|ARRAY/) || #書込値がリファレンスでない
!(-f "$lockdir/$lockfile") #ロック用のファイルが存在しない
);
$path = ">$path" unless ($path =~ /^>>?/); #先頭が > でも >> でもない
my $lockid = &fileLock($lockdir, $lockfile) or die &$busyfunc->() if ($lockdir); #ロック開始
open(WRITE, $path) || goto ERROR;
print WRITE (ref($line) eq 'SCALAR') ? $$line : @$line; #書込
close(WRITE);
&fileUnlock($lockid) if ($lockdir);
return;
ERROR:
&fileUnlock($lockid) if ($lockdir); #ロック解除
&$busyfunc->() if ($lockdir);
}
&virus::write($path, \@line, $lockdir, \&busyErrorFunction); #実行
&virus::write(
"ファイルのパス",
"書きこむ内容(スカラかリスト)のリファレンス",
"ロック用のディレクトリ(ないとロックしない)",
"ロックエラー時に実行される関数のリファレンス(ロックする時は必須)"
);
もうまるっきり別物です。リファレンスを使うことで、かなり効率が良くなったんじゃないかと思いますが、どうなんでしょう。このコンテンツの管理CGIではHTMLの生成時に100KB級の出力を大量にするので、採用したらそれなりに効果があるんじゃないでしょうか。
採用したら…というのも、書きこむ文字列をリファレンスで渡さないといけなくなったので、この関数を使ってる部分は全部修正しないといけないからです。ロック機構も実装してない(必要ないから)とはいえ、せっかくバグもなく快調に動いてるのに、その安定性を捨てるのはちょっと度胸がいります。
よって、今は絵日記CGIでのみの採用。
なにせ組むほどに新しい方法を会得していくから、下手に講座サイトとか見ると大変なことになります。
そして、俺は知ってます。JavaScriptで経験したから知ってます。この時期に組んだものは後に残らないということを。
初めてのプログラムだったJavaScriptと違い、今はプログラムのセオリーというのを少しは知っているから、Public Editionのような大カオス状態にはならないだろうけど、それでも上級者の超Perlを見てると今組んだものが残らないことは容易に想像できます。
JavaScriptを始めたての頃、上級者の超スクリプトを見ては不安になっていたものですよ。これ本当にJavaScript?と。
window.status = '...Now position... <siteCTS / Enter / Top / パチョ奮闘記 >';
こんなので感激していたかわいらしい俺も、今では
if (!(file = dir.pop()) && !(file = this.getDefaultIndex()[dir.pop()]))
なんてコードを小指だけで書けるくらい成長しました。時の流れというのは恐ろしいものです。
「ライブラリの仕様変更」というのは影響が全体に及ぶので、早いうちに煮詰めないといけません。
そして、俺は知ってます。JavaScriptで経験したから知ってます。ライブラリが煮詰まるには年単位の時間が必要であることを。
ちなみに、JavaScriptでは virus.js と vaccine.js というふたつのライブラリがsiteCTSを支えていて(普通に見ていると気づかないけど裏ではゴリゴリ動いてる)、4年目にしてようやく煮詰まってきたのか、最近はあまり修正されてないですね。
絵日記CGI〜本体を置き忘れて
2005.2.28.Mon
昨日は &write の改修を実施したわけですが、もちろん &read が存在します。というわけで今日はこいつを改修。別に今の状態でも充分使えるけど、今のスキルならもっともっと高機能にできるのです。できるのなら、やらねばなりません。
■改修前
sub read {
my ($path, $flag) = @_;
#パス末尾が / ならディレクトリ取得
if (substr($path, length($path) -1) eq '/') {
opendir(DIR, $path) || &error("directory open error $path at &virus::read()");
my @list = readdir(DIR);
closedir(DIR);
shift(@list); shift(@list); # . と .. を削除
@list = sort(@list);
return @list;
#それ以外はファイルの内容を取得
} else {
open(READ, "<$path") || &error("file open error $path at &virus::read()");
my @file = <READ>;
close(READ);
if ($flag eq 'print') { #出力
foreach (@file) {
print;
}
return;
} elsif ($flag eq 'chomp') { #要素末尾の改行コードを除去(データファイル読込用)
chomp(@file);
} elsif ($flag eq 'join') { #配列を結合
return join('', @file);
}
return @file;
}
}
&virus::read($path, $flag); #実行
&virus::read(
"ファイル/フォルダのパス",
"フラグ"
);
なにが気にくわないって、しょっぱなの
if (substr($path, length($path) -1) eq '/') {
です。パスの末尾が / だったらフォルダと判断しているわけですが、つけ忘れるとファイルと誤認識します。
これは「ファイルテスト演算子」を使って
if (-d $path) { # $pathがディレクトリだったら真を返す
にすれば一発解決かつ100倍エレガントなのに、それを知らないのが素人なんです。
それでも、この関数ひとつでフォルダの取得とファイルの内容取得を両方カバーできるのは便利です。難点といえば、フォルダ/ファイルを開くのに失敗した時、無条件にエラーストップしてしまうところですか。開こうとする場所が必ず存在する保証がない時は、まず最初に存在チェックしなければならず、これがとても面倒くさいのです。(読込用の関数は書込用に比べて、使用頻度が異常に高いから)
ライブラリは色々なところから呼び出されて共用されるからこそ、価値があります。従ってエラー時に実行したい処理もその時々によって違います。失敗した時にエラーストップさせなければいいだけの話だけど、それならそれで結果をいちいち確認せねばならず、結局は面倒くさい。
理想的なのは「エラーが起きた時だけ指定の関数を実行」なんですけど。
こんな悩ましい問題も、2.24に憶えた「リファレンス」を使えば一発解決です。実行時にエラー用の関数を引数で渡し、エラー時に実行させればいいわけです。関数をライブラリで用意せず、使う側に自分で用意させることで、エラー時の処理を自由に決められる。そして関数を渡さない時は、処理を止めずに偽を返す。
これによって、「対象が存在すればその内容を、しなければ偽を返す、関数を渡されていれば実行した後で偽を返す」という理想的な動作を実現できました。
そうこうしてできあがったのが新型 &read です。もうやりすぎです。
■改修後
sub read {
my $path = shift; #引数先頭を切取
&chop($path, '/'); #$pathの末尾が / なら除去
my $errfunc = pop if (ref($_[$#_]) eq 'CODE'); #引数末尾を切取
#オプションの取得
my ($tree, $dir, $file, $noslash, $i, $reverse, $length, $chomp, $print, $return, $filter);
foreach (split(/,/, shift)) {
$tree = 1 if (/^tree$/);
$dir = 1 if (/^dir$/);
$file = 1 if (/^file$/);
$noslash = 1 if (/^noslash$/);
$i = 1 if (/^i$/);
$filter = (split(/filter:/))[1] if (/^filter:.+/);
$reverse = 1 if (/^reverse$/);
$length = 1 if (/^length$/);
$chomp = 1 if (/^chomp$/);
$print = 1 if (/^print$/);
$return = 1 if (/^return$/);
}
#対象がディレクトリの時
if (-d $path) {
my (@alldir, @allfile);
if ($tree) {
my @dirlist = ($path);
while ($path = shift(@dirlist)) {
my @list = glob("$path/*"); #パス内の全オブジェクト
push(@dirlist, grep({-d} @list)); #ディレクトリのみ抽出(ループに追加)
push(@alldir, grep({-d} @list)); #ディレクトリのみ抽出
push(@allfile, grep({-f} @list)); #ファイルのみ抽出
}
} else {
opendir(DIR, $path) || goto READERROR;
my @list = grep{!m/^(\.|\.\.)$/g} readdir(DIR); # . と .. 以外のファイルを取得
closedir(DIR);
push(@alldir, grep({-d "$path/$_"} @list)); #ディレクトリのみ抽出
push(@allfile, grep({-f "$path/$_"} @list)); #ファイルのみ抽出
}
if (!$noslash) { #スラッシュ付加
foreach (@alldir) {
$_ .= '/';
}
}
if ($filter) { #フィルタリング
my @temp;
foreach (@allfile) {
my $filename = (split(/\//))[-1]; #ファイル名を抽出
if ($i) { push(@temp, $_) if ($filename =~ /$filter/i);} #フィルタにマッチしたら追加
else { push(@temp, $_) if ($filename =~ /$filter/);}
}
@allfile = @temp; #配列入れ替え
}
#ディレクトリだけ返す
return wantarray ? ($reverse ? reverse(sort(@alldir)) : sort(@alldir)) : $#alldir +1 if ($dir);
push(@allfile, @alldir) if (!$file); #ファイルとディレクトリ
return wantarray ? ($reverse ? reverse(sort(@allfile)) : sort(@allfile)) : $#allfile +1;
#対象がファイルの時
} elsif (-f $path) {
#サイズだけ
return -s $path if ($length && !wantarray && (-e $path));
open(READ, "<$path") || goto READERROR;
my @file = $reverse ? reverse(<READ>) : <READ>;
close(READ);
chomp(@file) if ($chomp);
print(@file) if ($print);
return if ($print && !$return); #(printの時にreturnがない)
return wantarray ? @file : join('', @file);
#存在しない
} else {
READERROR:
my $r = '';
$r = &$errfunc->() if (ref($errfunc) eq 'CODE'); #関数を渡されていれば実行
return wantarray ? () : ($length ? 0 : $r);
}
}
&virus::read($path, $option, \&openErrorFunction); #実行
&virus::read(
"ファイル/フォルダのパス",
"オプション(tree|file|dir|length|reverse|noslash|filter|i|chomp|print|return)"
"エラー時に実行される関数のリファレンス"
);
- 指定フォルダ以下、サブフォルダも含めてすべてのフォルダ/ファイルを取得できる
- フォルダだけ取得・ファイルだけ取得の指定ができる
- 取得するファイルを正規表現でフィルタリングできる
- フォルダ名の末尾に
/をつけるか選べる - ファイル取得の時は結合(
join)・末尾改行コード除去(chomp)・そのまま出力(print)を選べる。(改修前も選べたけど、受け判定の自動化でjoinオプションがなくなった)
これはちょっと良い感じになったと自画自賛です。なぜなら自分一人の力で作ったものではないからです。(grep まわりのコードはだいぶ講座サイトのお世話になっております)
そのおかげで、改修前とは比べものにならないほど多機能なものになりました。多機能すぎてオプションの憶え書きを書いておかないと作った本人さえ忘れてしまうくらい。
要点
- 受ける変数の型(スカラかリスト)で返す値が異なる。
- オプションはコンマ区切りで列挙する。意味のないもの(
fileとdirなど)を除き、同時指定可能。 - 引数末尾に関数のリファレンスを入れると、対象が存在しない時に実行される。
- 対象が存在しない時は空配列か空文字を返す。(関数を実行しても返す)
フォルダを取得する時のオプション
@dirlist = &read($path, "option", \&FunctionReference);-
返り値 = リストで受けるとフォルダ名のリスト、スカラで受けると見つかった数。
パスは末尾の/の有無を問わない。
tree-
サブフォルダを含むすべてのフォルダとファイルを拾う。このオプションを指定した場合、要素の中身は
admin/dir/admin/dir/file.txtadmin/dir/subdir/admin/dir/subdir/log1.datadmin/dir/subdir/log2.datadmin/img/admin/img/file1.png
渡したフォルダ(基点のフォルダ)自身は含まれない。 file- ファイルのみを取得する。
dirと同時指定不可。 dir- フォルダのみを取得する。
fileと同時指定不可。(fileが優先) noslash- フォルダ名の後ろに
/を付加しない。あたり前だがfileと同時指定しても無効。 reverse- リストで受けた時、配列を逆順にして返す。
length- フォルダが存在しない時、スカラで受けると空文字でなく0を返す。
filter:正規表現文字列- ファイル名を正規表現でフィルタリングする。ただし、構文上の制限でコンマを含めることはできない。(オプションの区切りにコンマでなく
|あたりを使えば簡単に解決できるけど) ifilterと同時指定時のみ有効。大文字小文字の区別をしない。
例:@list = &read($path, 'file,filter:^\d\d\.(jpe?g|png|gif)$,i');
→ 2桁の数字のjpeg,jpg,png,gifファイルのみ取得(大小区別なし)
ファイルを取得する時のオプション
@filelist = &read($path, "option", \&FunctionReference);-
返り値 = ファイルの内容。リストで受けると配列、スカラで受けると結合(
join)して返す。 chomp- リストを
chompしてから返す。設定ファイルの読込など、要素末尾の改行が不要の時に指定。 print- ファイルの内容をそのまま出力する。値は返さない。
chompの方が先に実行される。 returnprintと同時指定した時のみ有効。出力した後、その内容を返す。length- スカラで受けた時、ファイルサイズを返す。
ファイル取得はあまり変わってないけど、ディレクトリ取得は大げさすぎです。今までは「指定フォルダの中身」しか取れなかった(サブフォルダの中身まで取れなかった)のが、
@treelist = &virus::read($path, 'tree');
だけでサブフォルダ以下すべてを一発取得。(ついでにソートもされてる)
これがなにを意味するかっつと、フォルダの削除が簡単にできることです。通常は中身が入ってると削除できないフォルダが、別途 &removedir でも作れば一発削除。ごみ箱なんてのには行かないので1文字のミスが取り返しつかない事態に。
sub removedir {
my $path = $_[0];
foreach (&virus::read($path, 'tree,reverse')) {
-d $path ? rmdir : unlink;
}
return rmdir($path); #対象フォルダを削除
}
$result = &removedir('./folder'); #実行(成功したら $result に真が入る)
なにげに、noslash オプションをつけるとフォルダ名の末尾に / がつかなくなるのが(俺的には)結構大事だったりします。いや、普通のプログラミングセンスを持ってれば「オプションをつけると付加する」なんだけど、俺用なんだから俺に最適化するのが当然です。
まだ改修の余地があるとはいえ、ライブラリの関数に重要なのはあくまでも渡す引数と返ってくる値であり、これさえ同じなら中身はどうでもいいのですよ。その辺の拡張性も考えながら作ったので、ばっちり大丈夫ですよ。ええ。JavaScriptの経験で言わしてもらえば、思惑通りにいくわけがないですけど。
まぁ素人ゆえそこらはあきらめるしかないわけですが、とりあえず昨日改修した &write と同じく、この新型 &read は今作ってる絵日記CGIのみの採用で、siteCTSでのデビューは当分先っぽい感じです。(たぶん用語集CGIになるだろう)
ライブラリばかり手をつけて、肝心の本体が全然進んでません。なんだかなー。