„Ń„Á„çÊłÆź”
2003ÇŻ4·î
ąŁ €ł€Î„ÚĄŒ„ž€Ë€Ä€€€Æ ąŁ
„Ń„œ„ł„óŽŰ·ž€Î»š”ĄŁ„œ„Ő„È€«€é„ÏĄŒ„É€Ț€Ç€Ț€ó€Ù€ó€Ê€ŻĄŁ
2001ÇŻ€ŹșÇÀčŽü€ÇĄąĄÖ„Æ„„č„È€À€±€Ç90KBĄŚ€â„¶„饣
°ì»țŽü€Ș€È€Ê€·€Ż€Ê€Ă€ż€±€ÉĄąŽÉÍę€ÎCGIČœ€Ë€è€Ă€Æ©€òżá€ÊÖ€·ĂæĄŁ
»êčâ€Î„ì„ó„ż„ë„”ĄŒ„ĐĄŒ
2003.4.2.Wed
ĄĄ€ą€Ê€ż€ŹșŁž«€Æ€€€ëĄą€ł€Î„ÚĄŒ„ž€ŹĂÖ€€€Æ€ą€ë„”ĄŒ„ĐĄŒĄŁČ¶€Ź»È€Ă€Æ€€€ë„ì„ó„ż„ë„”ĄŒ„ĐĄŒĄŁÈŸÇŻĂ”€·Âł€±Ąą€è€Š€ä€Żž«€Ä€±€ż„ì„ó„ż„ë„”ĄŒ„ĐĄŒĄŁ„Ê„Š€Ç„ä„󄰀ʄì„ó„ż„ë„”ĄŒ„ĐĄŒĄŁœś€Î»Ò€Î€ż€á€Î€Á€ç€Ă€ÈH€Ê„ì„ó„ż„ë„”ĄŒ„ĐĄŒĄŁżÍ€ËÁŠ€á€ë€Î€Ź€Á€ç€Ă€Ô€êĂŃ€ș€«€·€€„ì„ó„ż„ë„”ĄŒ„ĐĄŒĄŁČńŒÒÌŸ€ŹÁÇ€ÇÀÖÌÌ„Ż„é„č€Ê€ż€áĄą€â€ŠĄÖVelvetĄŚ€È€€€ŠČńŒÒÌŸ€È€·€Æ°·€Ă€Æ€€€ë„ì„ó„ż„ë„”ĄŒ„ĐĄŒĄŁ
ĄĄ€œ€ì€Ç€€€ÆĄą€ł€ì°ÊŸć€ÎŸò·ï€Ï€Ê€”€œ€Š€ÊĄą»êčâ€Î„ì„ó„ż„ë„”ĄŒ„ĐĄŒĄŁ
{kind=link}
ĄĄ»ä€Ï„š„„č„ŃĄŒ„È„Ś„é„󥣀ɀ΄DŽŁ„ì„Ż„È„ê€Ç€âCGI»È€€ÊüÂêĄŁPerlĄŠRubyĄŠPHPĄŠSSIĄą€Ê€ó€Ç€â€Ž€¶€ìĄŁ.htaccess €â .htpasswd €â»È€š€Æ€ą€ż€êÁ°ĄŁ„”ĄŒ„ĐĄŒ„Ț„·„ó€ÎCPU€ÏÍŸÍ”€Î„ź„Ź„Ű„ë„ÄĄŁ€·€«€âŸŻżÍżôÀ©ĄŁ„Ç„Ł„č„ŻÍÆÎÌ€ÏÌ”Ćš€Î200MBĄŁ€”€é€Ë€Ï„”„Ö„É„á„€„ó€ŹÉžœàÉŐ°ĄŁ€Ș€Ț€±€Ë„áĄŒ„ë„”ĄŒ„ĐĄŒ€Ï IMAP ÂбțĄŁ€Ä€€€Ç€ËŸŠÍŃÍűÍŃČÄĄŁ€ą€Ț€Ä€”€šÆ±żÍłš€ËžÂ€Ă€Æ€Ï„š„íOK€Ê€ó€ÆÁ°ÂćÌ€Êč€Î”ŹÌóĄŁĄÊșÇžć€Î€ÏỀ˄á„ê„Ă„È€Ë€Ê€Ă€Æ€Ê€€€ó€Ç€č€ŹĄË
ĄĄ€”€ÆĄąHow match ?
ĄĄĆú€š€ÏÇŻ10000±ßĄá·î833±ßĄŁĄÊÉáÄÌĄą€ł€ì€À€±€ÎŸò·ï€òÍŚ”á€č€ë€È3ĄÁ4Ç܀όè€é€ì€Ț€čĄË
ĄĄ€œ€ó€Ê€ą€ëÆü€Ă€Æ€€€Š€«șŁÆüĄą»êčâ€Î„ì„ó„ż„ë„”ĄŒ„ĐĄŒ€«€é„áĄŒ„뀏ÆÏ€€€żĄŁÆâÍÆ€ÏĄÖ„Ś„é„óƱÇр΀ȘĂ΀逻ĄŚĄŁ€Ê€ó€Ç€âĄąœŸÍè€Î„é„€„ÈĄŠ„č„ż„ó„ÀĄŒ„ÉĄŠ„š„„č„ŃĄŒ„ȀȀ€€Ă€ż„Ś„é„óÀ©ĆÙ€ŹĄą4·î14Æü€ÇÇѻ߀”€ì€ë€œ€Š€ÇĄŁ€œ€ì€ËÈŒ€€ĄąČÁłÊ€ä„Ç„Ł„č„ŻÍÆÎÌ€âÊŃč耔€ì€ëĄą€ÈĄŁ€Ê€Ț€žŸò·ï€ŹÎÉ€€€À€±€ËĄą€ł€ì€Ă€Æ·ù€ÊÍœŽ¶€Ź€č€ë€è€ÍĄŁ€·€Ê€€Ą©
ĄĄÊŃččžć€ÎČÁłÊ€Ï„é„€„È„Ś„é„ó€ÈƱłÛĄŁ
ĄĄÊŃččžć€ÎÍÆÎ̀τš„„č„ŃĄŒ„È„Ś„é„ó€ÈƱÎÌĄŁ
ĄĄ€”€ÆĄąHow match ?
ĄĄĆú€š€ÏÇŻ3000±ßĄá·î250±ßĄŁ
ĄĄ€č€Ê€ï€ÁĄąĆÜĆó€ÎĂÍČŒ€ČĄŁ€Ä€„€«7łä°ú€Ç€č€èĄ©
ĄĄĄÊ€Á€Ê€ß€Ë„é„€„È„Ś„é„ó€ÎżÍ€ÏƱłÛ€Ç„š„„č„ŃĄŒ„È„Ś„é„ó€ò»È€š€ë€ł€È€Ë€Ê€ê€Ț€čĄË
ĄĄ€ą€Ą€óĄȘ€â€Š°ìÀž€Ä€€€ÆčÔ€€Ț€čĄȘ
ĄĄĄÄ€È€ÏÁÇÄŸ€ËŽî€Đ€Ê€€Ąą”ż€€żŒ€€»äĄŁŽÎżŽ€Î„Ż„©„ê„Æ„ŁĄÊÆÀ˄č„ÔĄŒ„ÉÌÌĄË€ŹÍî€Á€Æ€Ï°ŐÌŁ€Ê€€€Î€è€ÍĄŁ€Ț€·€Æ€äĄąÂ»±ŚÊŹŽôĆÀ€òłä€Ă€Æ€·€Ț€Ă€Æ€Ïž”€â»Ò€â€Ê€€€Î€è€ÍĄÊÄÙ€ì€ë€«€éĄËĄŁĂÍČŒ€Č€Ï€â€Á€í€óŽż·Ț€À€±€ÉĄą€œ€ÎÊŐ€Ź€Á€ç€Ă€È”€€Ë€Ê€ê€Ț€čĄŁ„”ĄŒ„ӄ耏Íî€Á€ë€Ż€é€€€Ê€éĄąœŸÍè€ÎČÁłÊ€ÎÊꀏ€€€€€ó€À€±€ÉĄŁĄÖ°Â€«€í€Š°€«€í€ŠĄŚ€òĂÏ€ÇčÔ€ŻYahĄûĄûBB€ß€ż€€€Ê€Î€Ïș€€ë€èĄŁ€É€Š€»€Ê€é”ÈÌîČȀˀ·€Æ€Û€·€€€ÊĄŁ
ĄĄ»êčâ€Î„ì„ó„ż„ë„”ĄŒ„ĐĄŒĄąlolipopĄŁŽèÄ„€Ă€Æ€Ż€À€”€€ĄŁ€Ô€í€ą€€Ï±ț±ç€·€Æ€Ț€č€èĄŁżż·ő€ÊŽé€ÇĄŁ€ł€ł€ÏsiteCTS€Îż·Ć·ĂÏ€Ê€Î€Ç€č€«€éĄŁ
- ÄÉ”Ą§2005.5.30
- ĄÄ€È€«€Ê€ó€È€«žÀ€Ă€È€€Ê€Ź€éĄąŒ«ÊŹ„É„á„€„ó€òŒèÆÀ€č€ëșʀ˄”„Ö„É„á„€„ó€òỀ΄”ĄŒ„ĐĄŒ€Űłä€êĆö€Æ€ë€ł€È€Ź€Ç€€Ê€€€ł€È€ŹÈŻłĐ€·€ż€ż€áĄąžœș߀ÏỀ΄ì„ó„ż„ë„”ĄŒ„ĐĄŒ€ò»È€Ă€Æ€€€Ț€čĄŁ
ĄÖ„·„§„ąĄŚ€Ű€ÎÊŁ»š€ÊŽŃÇ°
2003.4.5.Sat
ĄĄÉáĂÊ€«€éDOM€À€ÎDHTML€À€Î€È„č„Ż„ê„Ś„È€òÁÈ€ó€Ç€€€ë€ÈĄą€É€Š€âĄÖ„Ö„é„Š„¶€Î„·„§„ąĄŚ€ËÂĐ€č€ëÈœĂǀζłŠ€Ź€Ü€ä€±€Æ€Ż€ëĄŁNetscape6&7 €Ź1łä€Ë€âËț€ż€Ê€€„É„Ț„€„ÊĄŒ€Ê„Ö„é„Š„¶€À€Ê€ó€Æ€ł€ì€Ă€Ę€Á€â»Ś€Ă€Æ€Ê€€€·ĄąOpera €ÏIEĄŠNetscape €È„·„§„ą€òÊŹ€«€Áč瀊ĄąÉá”Ú„ì„Ù„ë€ËĂŁ€·€ż„Ö„é„Š„¶€Ç€ą€ëĄÄ€Ê€ó€Æ»Ś€Ă€Æ€€€ëĄŁ
ĄĄ€ł€Š€€€Ă€żžíǧŒ±€Ï€É€Î€è€Š€Ë°·€š€Đ€€€€€Î€À€í€ŠĄ©
document.getElementsByClassName()
2003.4.6.Sun
ĄĄÁ°Ąč€«€é”żÌä€Ë»Ś€Ă€Æ€ż€ó€À€±€ÉĄą€Ê€ó€Ç ECMAScript €Ë€Ï getElementsByClassName() €Ă€Æ„á„œ„Ă„É€Ï€Ê€€€Î€À€í€ŠĄŁgetElementsByTagName() €È€« getElementsByName() €Ï€ą€ë€Î€ËĄą€ł€ì€Ź€Ê€€€Î€ÏÉÔ»Ś”ĶˀȚ€ê€Ê€€ĄŁÆĂÄêÍŚÁǀ΄Ż„é„č€ò°ìłçÊŃččĄÄ€È€«€ä€ê€ż€€»țĄąÊŰÍű€À€È»Ś€Š€ó€À€±€É€Ê€ĄĄŁ
ĄĄĄÄ€È€€€Š€ï€±€Çșî€Ă€Æ€ß€żĄŁĄÖ»ŰÄꀷ€ż class €ÎÍŚÁÇ€òÇÛÎó€ÇŒèÆÀĄŚ€č€ë„á„œ„Ă„ÉĄŁ
document.getElementsByClassName = function (c, t) {
t = this.getElementsByTagName(t ? t : "*");
for (var i = 0, r = new Array(), l = t.length; i < l; i++)
if (t[i].className == c)
r[r.length] = t[i];
return r;
}
ĄĄdocument.getElementsByClassName("cName", "a"); €È€č€ë€ÈĄą<a class="cName"> €ÎÍŚÁÇ€òÇÛÎó€ÇÊ֔ѥŁÂè2°úżô€òŸÊÎŹ€č€ë€ÈĄąÁŽÍŚÁÇ€ŹÂĐŸĘĄŁ
ĄĄĆöÁł€Ê€Ź€é getElementsByTagName() €ËÂбț€·€Æ€Ê€€€È€€€±€Ê€€€Î€ÇĄąIE5°ÊčߥŠNetscape6°ÊčߥŠOpera6°Êč߀ǀ·€«Æ°€«€ÌĄŁ€Ç€âIE4€Ê€é document.all.tags() €È€€€ŠÆ±€ž”ĄÇœ€Î„á„œ„Ă„É€Ź€ą€ë€«€éĄą€Û€ó€Î€Á€ç€Ă€ÈÄŸ€č€À€±€ÇÂбț€Ç€€ëĄŁĄÊĆö„”„€„È€Î„č„Ż„ê„Ś„È€ÏIE4€òÂĐŸĘł°€Ë€·€Æ€ë€Î€ÇÉŹÍŚ€Ê€«€Ă€ż€êĄË
ĄĄ€œ€Š€€€š€ĐĄą€Ț€À getElementsByName() €òȱ€š€ż€Æ€ÎșąĄą€ł€ì€ÈƱ€ž€è€Š€ÊŽ¶€ž€ÇĄÖgetElementsById() €Ï€Ê€€€Î€«€Ë€ç€ŠĄ©ĄŚ€Ê€É€È»Ś€Ă€Æ€ż€Ê€ĄĄŁ»ŰÄꀷ€żID€ÎÍŚÁÇ€òÇÛÎó€ÇŒèÆÀĄÄ€Ă€ÆĄąHTML€ò€”€Ă€Ń€ê€ï€«€Ă€Æ€Ê€€ŸÚ”ò€Ç€č€ÊĄŁĄÊID€Ï€œ€ÎÊžœńĂæ€Ç„æ„ËĄŒ„Ż€Ç€Ê€€€È€€€±€Ê€€€Î€ÇĄąs€Ź€ą€Ă€Æ€Ï€€€±€Ê€€€èĄË
ĄĄąš€ł€ì€Ï„Ż„é„č€Î„á„œ„Ă„É€È€·€ÆŒÂÁő€·€Æ€ë€Î€ÇĄąŒÂșĘ€Ë€Ïą€È€Ê€Ă€Æ€€€ëĄŁ
//class="class1 class2"€ß€ż€€€ÊĄÖÂżœĆ„Ż„é„襌€Ë€âÂбț€·€żÀ””ŹÉœžœÈÇ
sakura.prototype.classes = function (c, t) {
var reg = new RegExp("(^| )" + c + "( |$)");
var i = 0, r = new Array(), t = this.tags(t ? t : "*"), l = t.length;
for (; i < l; i++)
if (t[i].className.match(reg))
r[r.length] = t[i];
return r;
}
„”ĄŒ„ĐĄŒ€È„íĄŒ„«„ë€ÎÊÉ€ò±Û€š€ÆĄÊ€œ€Î2ĄË
2003.4.7.Mon
ĄĄ1·î20Æü€Ëșî€Ă€żĄÖ„íĄŒ„«„ë„”ĄŒ„ĐĄŒÀÜÂł»ț€Ç€âIE€«€éÄŸÀÜ„Ő„Ą„€„ë€òł«€±€ëłÈÄ„„ł„ó„Æ„„č„ÈĄŚ€ŹĄą€É€Š€â»È€€€Ë€Ż€€€Î€Ç„ê„Ő„Ą„€„óĄŁ€ł€ì€Ï±Š„Ż„ê„Ă„Ż„á„Ë„ćĄŒ€ËĆĐÏż€·€Æ€Ș€ĄąÁȘÂò€č€ë€ÈIE€«€é„ÚĄŒ„ž€ÎURL€òŒèÆÀ€·€Æ„íĄŒ„«„ë„Ő„Ą„€„ë€Î„Ń„č€ËÀ°·Á€·Ąą€Șč„€ß€Î„Æ„„č„È„š„Ç„Ł„ż€Çł«€ŻĄÄ€È€€€Š„č„Ż„ê„Ś„ÈĄŁ„”ĄŒ„ĐĄŒÂŠ€Î„ÚĄŒ„ž€òž«€Æ€€€ë»ț€Ç€âÄŸ€Ç„Ő„Ą„€„ë€òł«€±€ë€Î€ÇĄą€È€Æ€âÊŰÍűĄŁ
ĄĄ€·€«€·ĄąĆö„”„€„È€Ï„Ç„Ő„©„ë„È„€„ó„Ç„Ă„Ż„č€Ë index.html €ò»ÈÍŃ€·€Æ€Ê€€ŽŰ·žŸćĄąURL€Ź http://127.0.0.1/transient/scn/psn/ €ß€ż€€€Ë„Ő„Ą„€„ëÌŸ€Ź€Ê€€»țĄąĄÖ€ł€Î„Ç„Ł„ì„Ż„È„ê€Î„Ç„Ő„©„ë„È„€„ó„Ç„Ă„Ż„č€Ï 03-2.html €Ç€ą€ëĄŚ€È€€€ŠŸđÊó€òÆÀ€é€ì€Ê€€€Î€Ç€ą€ëĄŁ€ż€È€š AnHTTPd €Ź .htaccess €ËÂбț€·€Æ€ż€È€·€Æ€âÌ”Íꥣ
ĄĄ€Û€È€ó€É€ÏĄÖ€œ€Î„Ç„Ł„ì„Ż„È„êÌŸ€ÈƱ€ž„Ő„Ą„€„ëÌŸĄŚ€Ç€ą€êĄąabc „Ç„Ł„ì„Ż„È„ê€Î„Ç„Ő„©„ë„È„€„ó„Ç„Ă„Ż„č€Ï abc.html €Ë€Ê€Ă€Æ€ë€ó€À€±€ÉĄąÉŹ€ș€œ€Š€€€Š€ï€±€Ç€Ï€Ê€€€Î€ŹÄË€€€È€ł€í€ÇĄŁĄÊ„ŃÊł€ß€ż€€€Ê„ł„ó„Æ„ó„Ä€Ç€ÏĄą„Ç„Ő„©„ë„È„€„ó„Ç„Ă„Ż„č€ò abc.html €ÇžÇÄê€č€ë€ÈĄą„Đ„Ă„Ż„Ê„ó„ĐĄŒ€òșî€Ă€ż»ț€ËžĆ€€”»ö€ÎURI€ŹÊŃ€ï€Ă€Æ€·€Ț€Š€Î€ÇĄË
ĄĄ€Ä€Ț€ë€È€ł€íĄą€É€ł€«€Ë„Ő„Ą„€„ëÌŸ€ÎŸđÊó€òœń€«€Ê€€€È€€€±€Ê€€ĄŁ€É€ł€Ëœń€Ż€«€ÈžÀ€š€ĐĄąĆöÁł abc.html €Ëœń€Ż€Î€Ź°ìÈÖłÎŒÂ€ÇÁကĄŁ€ł€ì€ò„č„Ż„ê„Ś„ȀǜŠ€š€Đ€€€€ĄŁĄÊ„č„Ż„ê„Ś„ÈËÜÂ΀ËÀßÄê€òœń€ŻŒê€â€ą€ë€±€ÉĄą€ł€ì€ÏÆŹ€Î°€€ÊęËĄ€ÀĄË
ĄĄ€·€«€·ĄąHTML€Ë€œ€ó€ÊÌ”°ŐÌŁŸđÊó€òœń€ŻŸìœê€Źž«€Ä€«€é€Ê€€ĄŁĄÖValid€ÊHTMLĄŚ€Ï€È€Ë€«€ŻÌÌĆĘ€Ż€”€€€Î€ÀĄŁ
ĄĄ€è€Š€ä€Żž«€Ä€±€żŸìœêĄą€œ€ł€Ï <meta> ÍŚÁÇĄŁĄÖ„Ő„Ą„€„ëÌŸĄŚ€Ï„á„ż€ÊŸđÊó€ÈžÀ€š€ë€«€éĄąÍŃĆӀȀ·€Æ€Ï Valid €À€í€ŠĄŁĆÔčç€ÎÎÉ€€€ł€È€ËĄąname °À€ÎÆ°șÄê”Á€”€ì€Æ€Ê€€ĄŁHTML lint €â„š„éĄŒ€òœĐ€”€Ê€€€·Ąą€œ€Š€€€š€Đ WWWC €â <meta name="WWWC" content="ččż·ŸđÊó"> €ò»È€Ă€Æ€€€ëĄŁHTTP „Ű„Ă„À€ËÍŸ·Ś€ÊŸđÊó€ŹÆț€Ă€Æ€·€Ț€Š€ŹĄąÌäÂê€Ï€Ê€€€Ï€ș€ÀĄŁ
ĄĄĄÄ·è€Ț€ê€À€ÊĄŁ
<meta name="filename" content="abc.html">
ĄĄ€ł€Î1čÔ€ò„Ő„Ą„€„ë€ËÆț€ì€Æ€Ș€Ąą
window.external.manuArguments.document.getElementsByName("filename")[0].content;
ĄĄ€È€·€ÆœŠ€š€Đ€€€€ĄŁ€”€é€ËĄą<meta name="filename"> €Ź€Ê€€»ț€Ï„š„éĄŒ€Ë€Ê€ë€Î€ÇĄąÎăł°œèÍęĄÊtry catch čœÊžĄË€ò»È€Ă€ÆĄÖ„š„éĄŒ€Ź”Ż€€ż€é index.html €òł«€ŻĄŚ€È€·€żĄŁindex.html €â€Ê€€»ț€ÏĄÄĂ΀é€ÌĄŁ
ĄĄ€Ț€żĄąWeb„”ĄŒ„ĐĄŒÂŠ€Î„ÚĄŒ„ž€òž«€Æ€€€ë»ț€Ç€âÄŸÀÜ„Ő„Ą„€„ë€òł«€±€ë€è€Š€Ë€·€żĄŁ„íĄŒ„«„ë€È„”ĄŒ„ĐĄŒ€Î„Ç„Ł„ì„Ż„È„êčœÂ€€ŹÆ±€ž€Ç€ą€ëÉŹÍŚ€Ź€ą€ë€ŹĄą°ă€ŠżÍ€â€œ€Š€œ€Š€€€Ê€€€Î€Ç€ÏĄŁ€â€Á€í€óĄąłșĆö€·€Ê€€„ÚĄŒ„ž€ÇŒÂčÔ€·€ż»ț€ÏÉáÄÌ€Ë view-source: €Çł«€Ż€Î€ÇĄąÉžœà€ÎĄÖ„œĄŒ„č€ÎÉœŒšĄŚ€Ï€ä€äÉÔÍŚ€Ë€Ê€ëĄŁĄÊCGI€äSSI€ÎœĐÎÏ·ëČÌ€òž«€ë»ț€ËÉŹÍŚĄË
<script type="text/jscript">
//ÀßÄêŽŰżô
function initialize(ServerList) {
//ł«€ł€Š€È€č€ëURL€ŹČŒ€Î„”ĄŒ„ĐĄŒ„ê„č„Ȁˀą€ë»țĄą°ÊČŒ€ÎÀßÄê€òĆŹÍŃ
//€œ€ì°Êł°€ä„íĄŒ„«„ë€Î»ț€ÏŽŰ·ž€Ê€·ĄÊ€œ€Î€Ț€Ț view-source: €Çł«€±€ë€Î€ÇĄË
//„íĄŒ„«„ë„Ő„Ą„€„ë€È€ß€Ê€č„”ĄŒ„ĐĄŒ€Î„ê„č„È
//„”ĄŒ„ĐĄŒ€È„íĄŒ„«„ë€Î„Ő„©„ë„ÀčœÀź€ŹÆ±€ž€Ç€Ê€€€ÈÀ”Ÿï€ËÆ°€«€Ê€€
ServerList["127.0.0.1"] = 1; //„”ĄŒ„ĐĄŒ€Ź http://127.0.0.1/ €ÎŸìčç
ServerList["cts.velvet.jp"] = 1;
//ServerList["www.MyServer.ad.jp"] = 1; //„”ĄŒ„ĐĄŒ€Ź http://www.MyServer.ad.jp/ €ÎŸìčç
//ł«€ł€Š€È€č€ë„Ő„Ą„€„뀏Ÿć”€Î„”ĄŒ„ĐĄŒ€À€Ă€żŸìč祹„”ĄŒ„ĐĄŒÌŸ€ÎÉôÊŹ€ò DocumentRoot €ËĂÖŽč€č€ë
//„Ő„©„ë„À€Î¶èÀÚ€ê€Ï \ €Ç€Ê€Ż / €ò»ÈÍŃ
DocumentRoot = "F:";
//DocumentRoot = "C:/My Documents/MyWebSite"; //„È„Ă„Ś„ÚĄŒ„ž€Ź€ą€ë„Ő„©„ë„À€Î„Ń„č(șÇžć€Ë / €ÏÆț€ì€Ê€€)
//Î㥧http://127.0.0.1/abc/top.html ąȘ C:/My Documents/MyWebSite/abc/top.html €ËĂ֎耷€Æ„Ő„Ą„€„ë€òł«€Ż
//„œĄŒ„č€òÉœŒš€č€ë„Æ„„č„È„š„Ç„Ł„ż€Î„Ń„č
//„Ő„©„ë„À€Î¶èÀÚ€ê€Ï \ €Ç€Ê€Ż / €ò»ÈÍŃ
EditorPath = "C:/Apps/Hidemaru/Hidemaru.exe";
//EditorPath = "C:/Windows/notepad.exe";
//„Ç„Ő„©„ë„È€Î„Ő„Ą„€„ëÌŸĄÊ„Ç„Ő„©„ë„È„€„ó„Ç„Ă„Ż„čĄË
//„Ő„Ą„€„ë€Ë<meta name="filename" content="„Ő„Ą„€„ëÌŸ">€Ź€ą€ë»ț€Ï€œ€Ă€Á€ŹÍ„Àè
DefaultIndex = "index.html";
//Ăí°Ő
//URL€Ź http://127.0.0.1/abc/ €Î€è€Š€ËĄÖ„Ő„Ą„€„ëÌŸ€Ź€Ê€€ĄŚŸìč祹Ÿć”€Î DefaultIndex €òÊ䎰€·€Ț€čĄŁ
//DefaultIndex €Î„Ő„Ą„€„뀏€Ê€€»ț€ÏÀ”Ÿï€ËÆ°€€Ț€»€óĄŁ
//.htaccess €Ê€É€Ç„Ç„Ő„©„ë„È„€„ó„Ç„Ă„Ż„č€òÊŃč耷€Æ€€€ëŸìč祹HTML€Î„œĄŒ„č€Ë
//<meta name="filename" content="page.html">
//€òÆț€ì€Æ€Ș€Ż€ÈĄąDefaultIndex €ÎÂć€ï€ê€Ë page.html €òÊ䎰€č€ë€è€Š€Ë€Ê€ê€Ț€čĄŁ
//DefaultIndex€â<meta>€âΟÊꀹ€ë»ț€ÏĄą<meta>€ŹÍ„À耔€ì€Ț€čĄŁ
//„Ő„Ą„€„뀏CGI€Î»ț€ÎĂí°Ő
//CGI€ÇHTML€òœĐÎÏ€č€ë»ț€ÏĄą
//<meta name="filename" content="perl.cgi">
//€Î€è€Š€Ë<meta>€âœĐÎÏ€·€Æ€Ș€Ż€ÈÂбț€Ç€€Ț€čĄŁ
//€Ê€ȘĄą<meta>„ż„°€Î name €ÎĂÍ€Ï脀߀˱ț€ž€Æ„«„č„ż„Ț„€„ș€Ç€€Ț€čĄŁ
MetaTagNameAttributeValue = "filename";
return ServerList;
}
//ËÜÂÎŽŰżô
function viewSrc(svr, ext) {
var l = ext.location, p = ext.location.href;
if (svr[l.host]) {
p = new String(p.match(/[^?#]+/));
if (p.charAt(p.length -1) == "/") {
//€ł€ł€ŹșŁČóÏĂÂê€ÎÉôÊŹ
try {
p += ext.document.getElementsByName(MetaTagNameAttributeValue)[0].content;
} catch(e) {
p += DefaultIndex;
}
}
p = p.replace("http://" + l.host, DocumentRoot);
(new ActiveXObject("Shell.Application")).ShellExecute(EditorPath, p);
} else
l.href = "view-source:" + l.href;
}
var DocumentRoot, EditorPath, DefaultIndex, MetaTagNameAttributeValue;
viewSrc(initialize([]), window.external.menuArguments);
</script>
ĄĄËèĆـ΀ł€È€Ê€Ź€éĄą„ł„á„ó„È€Ź„Đ„é€Ț€Ż”€ËțĄč€Ç€ą€ë€ł€È€ò€Š€«€Ź€ï€»€ëĄŁ€â€Á€í€ó€œ€ó€ÊÍœÄê€Ï€Ê€€€Î€À€±€ÉĄŁĄÊ„ì„ž„č„È„ê€ò€€€ž€é€Ë€ă€Ê€é€ó€Î€ÇÁÇżÍ€ÎŒê€Ë€ÏÉ通€Ê€€ĄË
ExpContextĄÊ€œ€Î2ĄË
2003.4.13.Sun
![[ ExpContext€Î„€„󄿥Œ„Ő„§„€„č / 8KB ]](/lfs/psn/03/0413ExpContext.png "8KB") ĄĄ2002.11.8€ËșîÀź€ò»Ï€á€ż ExpContext €ËĄą€è€Š€ä€Ż€Ț€Ă€È€Š€Ê„€„󄿥Œ„Ő„§„€„č€òșî€Ă€Æ€ä€Ă€żĄŁ€Ț€żĄą3Čó€Ë1Čó€ÏÆ°€«€Ê€€€È€€€ŠŒêËĄŸć€Î„Đ„°€âČțÁ±€”€ìĄą10Čó€Ë1Čó€Ț€Ç·Úžș€”€ì€żĄŁ
ĄĄ2002.11.8€ËșîÀź€ò»Ï€á€ż ExpContext €ËĄą€è€Š€ä€Ż€Ț€Ă€È€Š€Ê„€„󄿥Œ„Ő„§„€„č€òșî€Ă€Æ€ä€Ă€żĄŁ€Ț€żĄą3Čó€Ë1Čó€ÏÆ°€«€Ê€€€È€€€ŠŒêËĄŸć€Î„Đ„°€âČțÁ±€”€ìĄą10Čó€Ë1Čó€Ț€Ç·Úžș€”€ì€żĄŁ
ĄĄ±Š„Ż„ê„Ă„Ż„á„Ë„ćĄŒ€«€éŒÂčÔ€”€ì€ż„č„Ż„ê„Ś„È€ÏĄą„Š„Ł„ó„É„Š€Ê€É€Î„ł„ó„Æ„Ê€ò»ę€ż€Ê€€œăżè€Ê„č„Ż„ê„Ś„Ȁǀą€ëĄŁœèÍꀏœȘ€ï€êŒĄÂèĄąÂščïŸĂ€š”î€Ă€Æ€·€Ț€ŠĄŁœŸ€Ă€ÆĄąExpContext €Î€è€Š€Ê„€„󄿥Œ„Ő„§„€„č€òÍż€š€ë€ż€á€Ë€ÏĄą€œ€ł€«€é€”€é€Ë„Š„Ł„ó„É„Š€òł«€Ąąexternal „Ș„Ö„ž„§„Ż„È€ò€Š€Ț€ŻĆÏ€·€Æ€ä€é€Ê€€€È€€€±€Ê€€ĄŁ€ł€ì€Ź€É€Š€â€Š€Ț€Ż€€€«€Ê€€€Î€Ç€ą€ëĄŁ€Ê€ó€«ÎÉ€€„ą„€„Ç„ą€Ï€Ê€€€â€Î€À€í€Š€«ĄŁ
ĄĄ€ÇĄąČŒ€Î€Ő€ż€Ä€Ïż·€·€ŻÄÉČĂ€”€ì€ż”ĄÇœ€ÇĄą€€€ș€ì€â„”„€„ÈŽÉÍęÍрǀą€ëĄŁ
- ĄÖ€ł€Î„ÚĄŒ„ž€Î„Ő„©„ë„ÀĄŚ
URL€«€é„”ĄŒ„ĐĄŒ„ą„É„ì„č€ä„Ő„Ą„€„ëÌŸ€òŒè€êœü€Ąą„íĄŒ„«„ë€Î„Ń„č€ËÀ°·Á€·€Æ„š„Ż„č„Ś„íĄŒ„é€ò”ŻÆ°€č€ëĄŁ„”ĄŒ„ĐĄŒÂŠ€Î„ÚĄŒ„ž€òž«€Æ€€€ë»ț€Ç€âĄą„íĄŒ„«„ë€Î„Ő„©„ë„À€òł«€±€ëĄŁ - ĄÖ„”ĄŒ„ĐĄŒ„Á„§„󄞥Ś
„ëĄŒ„È€«€é€Î„Ń„č€Ï€œ€Î€Ț€Ț€ËĄą„”ĄŒ„ĐĄŒÌŸ€À€±€òÊŃč耷€Æ°ÜÆ°€”€»€ëĄŁ€ż€È€š€Đ„”ĄŒ„ĐĄŒÂŠ€Î„ÚĄŒ„ž€òž«€Æ€€€ë»ț€Ë "to local" €òÁȘ€Ù€ĐĄą€œ€Î€Ț€Ț„íĄŒ„«„늀΄ՄĄ„€„ë€Ë„ž„ă„ó„Ś€č€ëĄŁ
ĄĄșŁ€Î€È€ł€íĄąExpContext €Źł«€€€Æ€ë»ț€ËĄą€”€é€Ë ExpContext €òł«€ł€Š€È€č€ë€È„š„éĄŒ€Ź”Ż€€ë€Î€À€ŹĄą€ł€ì€ÏČò·è€č€ë€Ù€€À€í€Š€«ĄŁwindow.onblur = window.close; €Ç€â»Ć€ł€à€«Ą©
ExpContext.htmĄÊ„Š„Ł„ó„É„Š€òł«€ŻÆ§€ßÂæĄË ExpContext.htmlĄÊËÜÂÎĄË
- ÄÉ”Ą§2003.4.18
- 4.18€Ë€”€é€ËČțÎÉĄŁ„Đ„°€âČțÁ±ĄŁ
Dive into between 0 and 1.
2003.4.15.Tue
ĄĄ”Ś€·€Ö€ê€ËńÙ€ë”ĄČń€Ë·Ă€Ț€ì€ż€Î€ÇĄą€ȘÆÀ°Ő€ÎÄčÊž€Ç„áĄŒ„ë€ÎÊÖżź€Ë JavaScript €Î€ł€È€Ê€É±äĄč€Èœń€€€ż€Î€ÀĄŁ10KB€ÏÍŸÍ”€Çœń€€€ż€À€í€Š€«ĄŁ€ł€Î„Ń„Á„çÊłÆź”€Çč„€€Ê€À€±œń€€€Æ€ë€è€Š€Ëž«€š€ë€ŹĄąÈż±ț€òŽüÂÔ€·€Æ€ë€ï€±€Ç€â€Ê€±€ì€ĐĄąÏĂ€ÎÄÌ€ž€ëżÍ€Źž«€ëČÄÇœÀ€â€Ê€€„ł„ì€ÏĄąœêÁ§ "ÆÈ€êžÀ" €Ç€·€«€Ê€€ĄŁ°ì±țĄÖœń€€€ż€éËțÂĄą€ą€È€ÏĂ΀é€ÌĄŚ€Ç€ą€ë€Î€À€±€ÉĄą€ä€Ï€ê°ìÊęÄÌčÔ€è€ê€ăÁĐÊęžț€ÎÊꀏÎÉ€€€Ë±Û€·€ż€ł€ż€Ą€Ê€€ĄŁ
ĄĄ€Š€àĄŁ€Ê€«€Ê€«€ÎœĐÍè€ÀĄŁ
ĄĄ€·€«€·Ąą€ł€ì€ò€č€°€ËÁś€ë€è€Š€Êżż»ś€Ï€·€Ê€€ĄŁ€Ê€Ë€»ÁêŒê€ÏĂ΀é€Ê€€żÍĄŁ°ìÈŐÆóÈŐ€ÏżČ€«€»Ąą€ž€Ă€Ż€êżäÚÊ€č€ë€Î€Ç€ą€ëĄŁÎé”·€òÄÌ€·€ż„áĄŒ„ë€Ë€ÏĄąÎé”·€òÄÌ€·€żÊÖżź€ò€·€Ê€±€ì€Đ€Ê€é€Ê€€ĄŁ
ĄĄŒĄ€ÎÆüĄŁnPOPQ €ò”ŻÆ°€č€ë€ÈĄąșòÆüœń€€€ż„áĄŒ„뀏€É€ł€Ë€â€Ê€€ĄŁÁśżźÈą€Ë€â€Ê€€€·ĄąÊĘÂžÈą€Ë€â€Ê€€ĄŁ€ą€ż€êÁ°€À€ŹŒőżźÈą€Ë€â€Ê€€ĄŁ€Ș€ä€Ș€äĄŁ
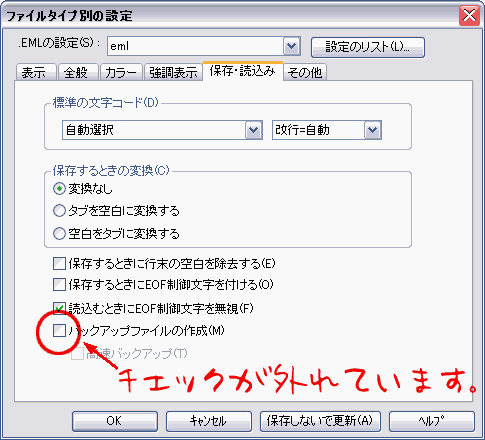
ĄĄnPOPQ €Ç€Ïł°Éô„š„Ç„Ł„ż€òÀßÄꀷĄą„áĄŒ„ëËÜÊž€ÏœšŽĘ€Çœń€€€Æ€€€ëĄŁžÀ€Š€Ț€Ç€â€Ê€ŻĄą»È€€Ž·€ì€ż„š„Ç„Ł„ż€ÎÊꀏœń€€ä€č€€€«€é€ÀĄŁ€œ€ł€ÇĂí°Ő€č€ë€Ù€€ÏĄąÉŹ€șœšŽĘ€òÀè€ËÊÄ€ž€Ê€€€È€€€±€Ê€€€ł€È€Ç€ą€ëĄŁnPOPQ €ÏœšŽĘ€ÎœȘλ€òžĄĂ΀·€ÆÆâÍÆ€òččż·€č€ë€ż€áĄąÀè€ËÊÄ€ž€Æ€·€Ț€Š€Èœń€€€ż„áĄŒ„뀏ččż·€”€ì€Ê€€€Ț€ȚŸĂ€š€Æ€·€Ț€Š€Î€ÀĄŁ
ĄĄ€Š€àĄŁ€œ€Š€€€š€ĐĄÄĄŁ
ĄĄ€Ê€ËĄą€ł€Š€€€Š»ț€ËÈś€šĄąœšŽĘ€Ë€ÏŒ«Æ°„Đ„Ă„Ż„ą„Ă„Ś€ŹÉŐ€€€Æ€€€ëĄŁŸÇ€ëÉŹÍŚ€Ê€É€É€ł€Ë€â€Ê€€ĄŁ€Ê€ó€ÈÊŰÍű€Ê„š„Ç„Ł„ż€Ê€Î€À€í€ŠĄŁ
ĄĄ€È€ł€í€ŹĄą„Đ„Ă„Ż„ą„Ă„Ś„Ő„©„ë„À€òĂ”€·€Æ€â€ȘÌÜĆö€Æ€Î„Ő„Ą„€„뀏€Ê€€ĄŁnPOPQ €ŹœšŽĘ€ŰĆÏ€č»ț€Ëșî€ë°ì»ț„Ő„Ą„€„ëÌŸ€ÏÆĂŒì€Ê€Î€ÇĄąŽÊñ€Ëž«€Ä€«€ë€Ï€ș€Ê€Î€À€±€ÉĄŁ€Ș€«€·€€ĄŁ€Ș€«€·€€ĄŁŸÇ€ëÉŹÍŚ€ŹœĐ€Æ€€żĄŁ
ĄĄ€Ț€”€«€È»Ś€Ă€ÆœšŽĘ€ÎÀßÄê€òłÎǧ€·€Æ€ß€ë€ÈĄąĄÄ€œ€ł€Ë€Ï€Ș·è€Ț€ê€Î„Ș„Á€Ź±Ł€”€ì€Æ€€€żĄŁ°ì±ț grep €ÇHD€ÎÁŽžĄșś€â»Ü€·€ż€ŹĄąĆÌÏ«€ËœȘ€ï€Ă€żĄŁ
{kind=link}
ĄĄ€ł€Š€·€ÆĄąÂż€Ż€Î»țŽÖ€òÈń€ä€·€Æœń€Ÿć€Č€ż„áĄŒ„ë€ÏĄą0€È1€Î¶čŽÖ€Ű€ÈŒș€ï€ì€żĄŁ„ÇĄŒ„ż€òŒș€Š€ł€È€ÎÈá·à€òČżĆÙ€âÌŁ€ï€€ĄąĄÖ„Ç„Ł„ž„ż„ë€ÎŒćĆÀĄŚ€òČżĆÙ€âÄËŽ¶€·Ąą„Đ„Ă„Ż„ą„Ă„Ś€ÏÇ°Æț€ê€Ë€ä€Ă€Æ€€€ëȶ€Ç€âĄą€ł€Š€€€Š»öÂÖ€ÏČóÈò€Ç€€Ê€€ĄŁ€ł€ì€À€«€é„Ç„Ł„ž„ż„ë€Ï·ù€Ê€Î€ÀĄŁ
ĄĄŽèÄ„€Ă€Æœń€ÄŸ€·€Ï€·€ż€â€Î€ÎĄą€ą€ì€À€±€ÎÎÌ€òÉüž”€č€ë€Î€ÏÉÔČÄÇœ€Ç€ą€êĄą€Ê€Ë€è€ê”€ÎπλțĆÀ€Ç°ÊÁ°€òĶ€š€ë€â€Î€Ïœń€±€Ê€«€Ă€żĄŁ
ĄĄ€Ț€ł€È€Ë€·€ç€ó€Ü€ê€Ç€ą€ëĄŁ
ExpContextĄÊ€œ€Î3ĄË
2003.4.18.Fri
ĄĄ4.13€Ë„ĐĄŒ„ž„ç„ó„ą„Ă„Ś€·€ż€Đ€Ă€«€Î ExpContext €òĄą€”€é€Ëșî€êÄŸ€·ĄŁčœÂ€Ÿć€Î„Đ„°€Ź€Ț€À»Ä€Ă€Æ€€€ÆĄą€É€Š€Ë€â”€ÊŹ€Ź°€€€«€é€ÀĄŁ3.16€ÇžÀ€Ă€Æ€ż€è€Š€ÊĄÖčüłÊ€Î»țĆÀ€ÇŽÖ°ă€š€Æ€ëĄŚÎà€€€Î„Đ„°€Ê€Î€ÇĄą€â€ŠșŹ€Ă€ł€«€éÁȀ߀ʀȘ€čÉŹÍŚ€Ź€ą€ëĄŁĄÊ€È€€€Ă€Æ€âĄą€Ț€À”ŹÌÏ€Ź€Á€Ă€Á€ă€€€Î€Ç¶ìÏ«€·€Ê€«€Ă€ż€±€ÉĄË
- ŒÂčÔ€”€ì€ë
- ExpContext €ò”ŻÆ°ĄÊExpContext.html €òż·”Ź„Š„Ł„ó„É„Š€Çł«€ŻĄË
- „Š„Ł„ó„É„Š„Ș„Ö„ž„§„Ż„È€Źșî€é€ì€ë€Ț€ÇÌ”ẦʷŚ»»€Ç€â€·€Æ»țŽÖČÔ€ź€ò€č€ë
external„Ș„Ö„ž„§„Ż„È€òĆÏ€č- Œ«ÊŹ€ÏœȘλ
ĄĄșŁ€Ț€Ç€ł€Î€è€Š€Ê„Ś„í„»„č€À€Ă€ż€Î€À€±€ÉĄą4. €Ç external „Ș„Ö„ž„§„Ż„È€ò€Š€Ț€ŻĆÏ€»€Ê€€€ł€È€ŹÂż€«€Ă€ż€Î€Ç€ą€ëĄŁ€È€€€Š€«Ąą€É€ŠčÍ€š€Æ€â 3. €ŹÈț€·€Ż€Ê€€ĄŁ
ĄĄ€œ€ł€ÇĄą€ł€ì€ò
- ŒÂčÔ€”€ì€ë
- ż·€·€€„Ö„é„ó„Ż„Š„Ł„ó„É„Š€òł«€Ż
- ExpContext €ÎHTML€òœń€œĐ€·
- HTMLĂæ€Ë JavaScript €â°ìœï€Ëœń€œĐ€č
external„Ș„Ö„ž„§„Ż„È€òĆÏ€č- Œ«ÊŹ€ÏœȘλ
ĄĄĄÄ€È€€€Š„Ś„í„»„č€ËČțÎÉĄŁHTML€ò JavaScript €Çœń€œĐ€č€Î€ÏÌÌĆĘ€Ż€”€€€Î€ÇÈò€±€ż€«€Ă€ż€Î€À€±€ÉĄąĂŚ€·Êę€Ê€€ĄŁ„č„Ż„ê„Ś„ÈËÜÂÎ€Ïł°Éô„Ő„Ą„€„ë€Ë€·ĄąÊÌĆÓ„íĄŒ„É€č€ë€ł€È€Ë€·€żĄŁ€ł€ì€Ë€è€êĄąĄÖ”ŻÆ°ÍŃĄŠËÜÂÎĄŚ€È€€€Š2„Ő„Ą„€„ëčœÀź€«€éĄąĄÖ”ŻÆ°ÍŃĄŠ„č„Ż„ê„Ś„ÈĄŠÉœŒšÍŃCSSĄŚ€Î3„Ő„Ą„€„ëčœÀź€È€Ê€Ă€żĄŁĄÊËÜÂÎ€Ï„č„Ż„ê„Ś„È€«€éÀžÀź€”€ì€ëĄË
ĄĄ·ëČÌĄą„Đ„°€Ïž«»ö€ËČțÁ±€·ĄąÂÔ”ĄÍŃ€ÎÌ”ÂÌœèÍę€â€Ê€Ż€Ê€Ă€Æ·ÚČś€ËÆ°€Ż€è€Š€Ë€Ê€Ă€żĄŁ€è€·€è€·ĄŁ
ÂçÉüłèĄȘ„€„ó„Ç„Ă„Ż„č„”ĄŒ„Á
2003.4.21.Mon
ĄĄČá”îĄÊ2001ÇŻËö€ą€ż€êĄËĄąsiteCTS€Ë€Ï„€„ó„Ç„Ă„Ż„č„”ĄŒ„Á€È€€€Š”ĄÇœ€Ź€ą€Ă€żĄŁ„È„Ă„Ś€Î index.html €Ë°úżô€òĆÏ€·€Æ€ä€ë€ł€È€ÇĄąÌÜĆȘ€Î„ÚĄŒ„ž€Ű„ȘĄŒ„È„ž„ă„ó„Ś€”€»€ë€â€Î€ÀĄŁ
ĄĄŒÂÎ㥧http://cts.creasus.net/public/index.html?dir=snp&anc=011216
ĄĄ€ł€Î”ĄÇœ€Ï„Ő„Ą„€„ëÌŸ€Ê€É€ŹÊŃč耔€ì€Æ€âœÀÆđ€ËÂĐœè€Ç€€ë€È€€€ŠÂ瀀ʄá„ê„Ă„È€Ź€ą€Ă€ż€ŹĄąJavaScript €ò»È€Ă€ÆŒÂžœ€·€Æ€€€ë€ż€áĄąÈóÂбț„Ö„é„Š„¶€À€Ă€ż€ê”ĄÇœ€Ź„Ș„Ő€À€Ă€ż€ê€č€ë€ÈÌ”žú€Ë€Ê€ëĄąĂŚÌżĆȘ€Ê·çĆÀ€Ź€ą€Ă€żĄŁ€œ€ì€Ź€æ€š€ËĄą€Û€È€ó€É»È€ï€ì€ë€ł€È€Ï€Ê€«€Ă€żĄŁ
ĄĄ€œ€ó€Ê¶ì€€ÁÛ€€œĐ€«€é1ÇŻÈŸĄŁŸő¶·€ÏÊŃ€ï€Ă€żĄŁsiteCTS€ÏCGI€Î»È€š€ë„”ĄŒ„ĐĄŒ€Ű°ÜĆŸ€·ĄąČ¶€âŸŻ€·€ÏPerl€ò»È€š€ë€è€Š€Ë€Ê€Ă€żĄŁ
ĄĄ€ŽÂžĂ΀ÎÄÌ€êĄąCGI€Ï„Ö„é„Š„¶€Ë°Íž€·€Ê€€€Î€ÇĄąJavaScript €Î€è€Š€Ê·çĆÀ€Ź€Ê€€ĄŁ„€„ó„Ç„Ă„Ż„č„”ĄŒ„Á€Î€è€Š€Ë„Ö„é„Š„¶°Íž€Ç€Ïș€€ë”ĄÇœ€ÏĄą€Ț€”€ËCGI€ÎÆÈĂĆŸì€Ê€Î€ÀĄŁ
ĄĄ€ł€Î„Ń„Á„çÊłÆź”€Ç€ÏĄąČá”î”»ö€Ű€Î„ê„ó„Ż€ŹÉŃÈˀˀą€ëĄŁ€·€«€·șŁž«€Æ€€€ë Transient Edition €Î„Ń„Á„çÊłÆź”€Ë€ÏĄą2002ÇŻ1·î°ÊÁ°€Î”»ö€Ź€Ê€€€ż€áĄą„Đ„Ă„Ż„Ê„ó„ĐĄŒ€Î»ČŸÈ€Ï€č€Ù€Æ„ê„Ë„ćĄŒ„ą„ëÁ°€Î„”„€„ÈĄÊPublic EditionĄË€ŰÏą€ì€ÆčÔ€ŻĄŁ
ĄĄ€ŹĄą„ê„Ë„ćĄŒ„ą„ëžć€Î Valid Edition €Ç€ÏĄą€č€Ù€Æ€Î”»ö€ŹŒę€á€é€ì€ëĄŁ€Ä€Ț€êĄąÄÌŸï€Ç€ą€ì€ĐÁŽÉô€Î„ê„ó„Ż€ò Valid Edition ÍŃ€Ëœ€À”€·€Ê€€€È€€€±€Ê€€ĄŁ€ł€ł€Ë„€„ó„Ç„Ă„Ż„č„”ĄŒ„Á€ò»È€Š€ł€È€ÇĄą
#index.cgi€Î°ìÉô
#2001ÇŻĄÁ2002ÇŻ1·î
if ($sY eq '01' || ("$sY$sM" eq '0201')) {
if ("$sY$sM" eq '0101') { #2001ÇŻ1·î€Î”»ö€Ïžș߀·€Ê€€
&err('&shortIndexSearch().snp.date.failed');
}
$e = 'public'; #Public Edition
$c = 'snp'; #„ł„ó„Æ„ó„Ä
$f = "$sY$sM/_$sY$sM.html"; #„Ő„Ą„€„ë€Î„Ń„č
if ($sD ne '') {
$a = int($sD); #ÆüÉŐ„ą„ó„«ĄŒ
}
}
ĄĄ€ł€ÎÉôÊŹ€ò€Á€ç€Á€ç€Ă€Èœ€À”€č€ë€À€±€Ç€€€€€Î€ÀĄŁČèŽüĆȘ€Ç€Ï€Ê€€€«ĄŁ
ĄĄ„€„ó„Ç„Ă„Ż„č„”ĄŒ„ÁCGI€ÏĄąhttp://cts.creasus.net/index.cgi €Ë€ą€ëĄŁ€”€é€ËĄą.htaccess €Ç€ł€ì€ò„Ç„Ő„©„ë„È„€„ó„Ç„Ă„Ż„č€ËÀßÄꀷ€Æ€€€ëĄŁindex.html €ò»È€Ă€Æ€Ê€€€Î€ÇĄąĂŻ€«€Ź„ê„ó„Ż€č€ë»ț€Ë index.html €òŽ·œŹĆȘ€ËÉŐ€±€Æ€·€Ț€Ă€żŸìč祹·ÙčđČèÌÌ€ŹÂÔ€Ă€Æ€€€ëĄŁ
ĄĄ€Ț€żĄąindex.cgi €ÏĄą°úżô€Ź€Ê€±€ì€ĐžœčÔÈÇ€Î„È„Ă„Ś„ÚĄŒ„ž€Ë„ê„À„€„ì„Ż„È€č€ë€·Ąą?index €òÍż€š€ì€ĐÎòÂćsiteCTS€ÎÁȘÂòČèÌÌ€òœĐÎÏ€č€ëĄŁ
ĄĄ€ł€Š€€€Šż§Ąč€Ê”ĄÇœ€ò <a href="/?xxx"> €À€±€ÇŽÊñ€Ë»È€š€ë€Î€À€«€éĄą€Ț€ł€È€ËÊŰÍű€ÈžÀ€ŠÂŸ€Ê€€ĄŁ„”„Ö„É„á„€„óÉŐ€€Î„”ĄŒ„ĐĄŒ€Ê€é€Ç€ÏĄą€Ç€ą€ëĄŁ
- ąŁhref="/"
<a href="/">€È€ä€ë€ÈĄąĄÖ„ëĄŒ„È€«€é€Î„ф襌€Ë€Ê€ëĄŁ
Ćö„”„€„ȀΟìčç€Ï<a href="http://cts.creasus.net/">€ÈƱ€ž°ŐÌŁĄŁ
<a href="/aaa/bbb.html">€Ê€é<a href="http://cts.creasus.net/aaa/bbb.html">€ÈƱ€ž°ŐÌŁĄŁ
€ł€ÎŸìčç€Ï„Ç„Ő„©„ë„È„€„ó„Ç„Ă„Ż„č€ò index.cgi €Ë€·€Æ€€€ë€Î€ÇĄą€Ä€Ț€ê
<a href="/?xxx">
€Ï
<a href="http://cts.creasus.net/index.cgi?xxx">
€ÈƱ€ž€ł€È€Ë€Ê€ëĄŁ
ÊŰÍű€Ç€Ï€ą€ë€±€ÉĄą„íĄŒ„«„ë€Î»ț€ÏĄÖ„É„é„€„Ö€«€é€Î„ëĄŒ„ÈĄŚ€Ë€Ê€ë€Î€ÇĄąœéżŽŒÔ€Ë€Ï»È€€€Ë€Ż€€ĄŁĄÊ„”„€„È„ÇĄŒ„żÀìÍр˄Ʉ鄀„Ö€òÍŃ°Ő€·€Ê€€€ÈĄą„Æ„č„È€â€Ç€€Ê€€ĄË
ÊÖ€êș逜ĆÈą
2003.4.30.Wed
ĄĄÉŐ°Éʀⷀ€Ąą2002.12.19€ËŒșÇÔ€·€ż„ÎĄŒ„È„Ń„œ„ł„ó€Î„»„Ă„È„ą„Ă„Ś€ò€ä€Ă€È€łŽ°Î»ĄŁ€È€Ë€«€ŻŒĄ€«€éŒĄ€Ű€È„È„é„ք뀏”Ż€€ÆĄą€ä€ż€é€á€Ă€ż€é¶ìÏ«€·€Æ€·€Ț€Ă€żĄŁ€ł€ì€À€«€éžĆ€€„Ń„œ„ł„ó€Ï·ù€€€Ê€ó€ÀĄŁ
Œç€Ê„»„Ă„È„ą„Ă„ŚÆâÍÆ
- „ÏĄŒ„É„Ç„Ł„č„Ż€ÎÎΰèÊŃčč
- 3GB€ò„·„č„Æ„à2GBĄą„ÇĄŒ„ż1GB€Ëłä€êż¶€ëĄŁĄÄ€Ä€â€ê€ŹĄąOS€òC„É„é„€„Ö„»„Ă„È„ą„Ă„Ś€·€ż€éĄą€Ê€Œ€«”Հ˥Ł”쌰€Î NEC98Note €Ç€ą€ë€ż€áĄą„·„č„Æ„à„É„é„€„Ö€ŹA€Ê€Î€«C€Ê€Î€«Ê¶€é€ï€·€€ĄŁ€Ż€œ€ŠĄŁ
- OS€ÎșÆ„»„Ă„È„ą„Ă„Ś
- Windows98SE €Ï„Ç„Ő„©„ë„È€ÇIE5.0€Ê€Î€ÇĄą€ż€À€Î Windows98 €Ű„À„Š„ó„°„ìĄŒ„ÉĄŁ€ł€Î„»„Ă„È„ą„Ă„Ś€Ç€ÏIE4€òłÍÆÀ€č€ë€Î€ŹșÇÂç€ÎÌÜĆȘ€Ê€Î€Ç€ą€ëĄŁ”ŻÆ°„Ç„Ł„č„Ż€«€é„č„„ă„ó„Ç„Ł„č„Ż€ò„ф耷€ÆOS€Î„€„ó„č„ÈĄŒ„ëČèÌÌ€ËĂ©€ê€Ä€Ż€Ț€Ç€Ź°ìÈÖÂçÊŃ€À€Ă€żĄŁ
- LAN€Î„»„Ă„È„ą„Ă„Ś
- CD-ROM €Ź€è€Š€ä€Ż»È€š€ë€è€Š€Ë€Ê€êĄąLAN„«ĄŒ„ɀ΄Ʉ鄀„Ѐ℀„ó„č„ÈĄŒ„ëÀźžùĄŁÀă»Ò€Á€ă€ó€È€ÎÀÜÂł€â€Ê€ó€Ê€ŻÀźžù€·Ąą„€„ó„č„ÈĄŒ„ë€č€ë„ą„Ś„ꄱĄŒ„·„ç„ó€Î„Ő„Ą„€„ëžòŽč€âŒÂ€Ë„č„àĄŒ„șĄŁĄÊ€ł€ì€Ź€Ê€€€ÈĄą€€€Á€€€Á CD-R €ËŸÆ€€€Æ°Ü€·€ÆĄÄ€Ê€É€È€€€Ă€ż”€€Î±ó€€șî¶È€ŹÉŹÍŚ€Ç€ą€ëĄË
- Netscape3 €Î„€„ó„č„ÈĄŒ„ë
- Netscape2 €â„€„ó„č„ÈĄŒ„뀷€Æ€ß€ż€ŹĄąÍžúŽüžÂÀÚ€ì€È€«€Ç Netscape €Î„”„€„È€«€éœĐ€·€Æ€â€é€š€șĄą3.3Gold €òÁȘÂòĄŁĄÊ»ț·Ś€òÌျ€Đ»È€š€ë€±€ÉĄË
- „íĄŒ„«„ë„”ĄŒ„ĐĄŒ€Î„»„Ă„È„ą„Ă„Ś
- AnHTTPd €È ActivePerl €ò„€„ó„č„ÈĄŒ„륣AnHTTPd €Î„É„„ć„á„ó„È„ëĄŒ„È€ÏLAN·ĐÍł€ÇÀă»Ò€Á€ă€ó€ËÀÜÂłĄŁ€Ä€Ț€êÀă»Ò€Á€ă€óŠ€Ç„”„€„È„ÇĄŒ„ż€òÊŃčč€č€ì€ĐĄą€œ€Î€Ț€ȚœĆÈą€Ç€âččż·€”€ì€ëĄŁĆöÁł€Ê€Ź€éÀă»Ò€Á€ă€ó€Ź”Ż€€Æ€Ê€€€È»È€š€Ê€€ĄŁ
ĄĄĄÄ€ÈĄą€Ê€ó€È€«€Š€Ț€Ż€€€Ă€ÆÎÉ€«€Ă€żÎÉ€«€Ă€żĄŁ„á„€„óPC€È€·€ÆÀă»Ò€Á€ă€ó€Ź€€€ë°ÊŸćĄą„Í„Ă„È€ËÀÜÂł€Ç€€Ê€«€Ă€ż€é„Ž„߀À€«€é€Ê€ĄĄŁ
{kind=link}
- ÄÉ”Ą§2004.4.12
- ĄÖAnHTTPd €Î„É„„ć„á„ó„È„ëĄŒ„È€ò„ê„âĄŒ„Ȁˀč€ë€Ż€é€€€Ê€éĄąÁÇÄŸ€Ë http://yukiko/ €Ç„ą„Ż„»„č€č€ì€ĐĄ©ĄĄ€œ€ÎÊꀏ„Ü„í„ÎĄŒ„ȀˀâÍ„€·€€€ó€ž€ă€Í€š€ÎĄ©ĄŚ€È€€€Ă€żÎà€€€Î„Ä„Ă„ł„ß€Ï¶Ű»ßĄŁ